
无论那才刚进入行业的数据库管理员,还是正处于学习 SQL 阶段的开发人员,配置数据库,操作它,都没办法避开、绕开去,非得理解其核心概念才行。
市面上有关关系数据库的教程数量不少,然而,能够将理论讲解透彻,与此同时,还与具体查询语言实操相结合的教程,数量并不多。
不少人认为 Sybase 数据库配置繁杂,实际上,只要把握了关系模型的实质内容,以及 Transact-SQL 的基础用法,着手去操作并没有像所想象的那般困难。
今儿个咱就从最为基础的二维表结构开始讲起,一步一步引领着你去写出第一条查询语句。
关系模型的核心:二维表
关系数据库的逻辑结构事实上如同一张张二维表,每一张表都是以行和列构成的。
数据的属性是由列来定义的,像“作者姓名”,还有“书籍价格”也属于这列定义范围,具体一条条记录则体现为行。
你于 Sybase 数据库配置期间,首要之事便是将这些表的结构规划妥当。
如此这般的设计是极其契合人的那种带有直觉特性的思维的,你是绝对能够将其加以想象进而使之成为一个 Excel 表格的。
数据于每个格子里所呈现的应是不可再进行分割的,每一行具备独一无二的特性,此即为关系模型的基本要求。
认识到了这一要点,而后着手去开展 Transact - SQL 的操作,便会觉得轻松许多。
SQL 语言的四大组成部分
想要用好数据库,必须熟悉SQL 语言的四个主要部分。
第二是数据操作语言(DML),主要负责增删改查。
第三是数据控制语言(DCL),管理用户权限。
第四是事务控制语言,保证数据的一致性。
在Sybase 数据库配置过程中,DDL 语句用得最多。
还有一点值得提及的是 ODBC 机制,它使得应用程序并非直接与 DBMS 进行交互,而是借助统一的驱动程序来实施操作,如此一来,你的代码便能够在不同的数据库平台上运行。
使用 SELECT 子句选择列
查取数据属于工作里最为频繁的一项操作,SELECT 命令为起到这样作用的关键工具。
用法最为简单的一种情况,乃为进行 select 操作,其操作之后紧跟的是 from publishers,当中的星号所代表的含义,是返回表里面的所有列。
要是你仅仅是打算去看特定的信息,那就于像 select au_lname, au_fname from authors 这般来操作,仅仅去挑选姓氏以及名字所对应的列。
在进行查询操作之际,是还支持运用表达式的,举例而言,像是 select title_id, total_sales price from titles 这般的情况,能够直接将总销售额计算出来。
最开始着手接触 Transact - SQL 的那些人,给出的建议是先由这种简易的列选择开启练习。
利用 DISTINCT 消除重复
有些时候,查询所得的结果之中,会存在不少重复的行,在这样的时刻,DISTINCT 关键字便发挥其作用了。
就拿 select au_id from titleauthor 这条语句来讲,如果一个作者 ID 对应着多本书籍,那么结果就会出现重复的情况。
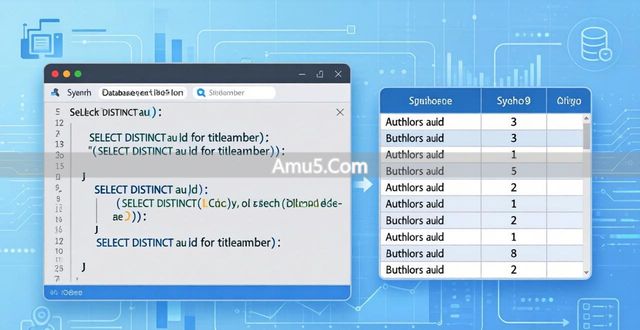
加了 select distinct au_id from titleauthor 之后,每个作者 ID 仅呈现一回。每个作者 ID 只显示一次。
这项功能于数据分析之际尤为实用,可助力你迅速弄明白表格之中究竟存有多少不重复的记录。
在处于 Sybase 数据库配置的测试时期那段阶段,运用 DISTINCT 去验证数据的唯一性这一行为是一种良好的习惯。
WHERE 子句与 IN 列表
WHERE子句用来指定搜索条件,只返回满足条件的行。
例如,你若想要寻觅某个州的作者,那么能够撰写 where state ="CA",或者撰写 where state ="IN"。
但如果条件比较多,这样写会很长。
较更为优雅的一种写法是采用 IN 关键字,即 where state 处于("CA""IN""MD")之中。
反过来想排除某些值,就用NOT IN。
“IN”最为强大的运用方式是与子查询相结合,举例来说,像这样的语句“select au_lname from authors where au_id in (select au_id from titleauthor where royaltyper < 50)”,这般的嵌套查询能够一次性达成复杂的需求。
GROUP BY 与 HAVING 的使用
当你有对数据展开分组统计的需求之际,GROUP BY 是绝对不能缺少的东西。
它常常与 avg()一同出现,它也时常和 sum()一块儿出现,它还经常跟 count()这般的集合函数一起出现。
比如你想看不同出版商的平均价格,就可以按 pub_id 分组。
有一点需要留意,HAVING 子句是专门用以过滤分组之后的结果哒,它跟 WHERE 不一样哟,WHERE 是在进行分组之前对行展开筛选,而 HAVING 是在分组完毕之后对组进行筛选。
一种典型的、具有代表性的写法是,选取 pub_id,计算 titles 中 price 的平均值,依据 pub_id 进行分组,并且设定条件为平均价格大于 15。
掌握这个顺序,复杂统计查询就不难写了。
ORDER BY 排序技巧
数据被查询出来后,其呈现状态默认是没有顺序的,若想要依据某种特定规则来进行排列,那么就需要运用 ORDER BY。
你可以根据一个或多个列进行排序,最多支持 31 个列。
诸如 select pub_id, type, title_id from titles 以那种方式进行排序,也就是 order by pub_id,最终得出的结果将会依照出版社 ID 排列好。
要是先进行分组随后再排序,那具体的写法是会显得颇有自然之感,会这样写:select type, 平均(price) from titles 依据 type 进行分组 按照平均(price)来排序。
这儿存在一个小窍门,你能够运用列的位置编号去替代列名,举例而言,order by 2 意味着依据第二列进行排序。
在 Sybase 数据库进行配置时,于查询优化这个过程当中,合理的排序能够极大程度地提升数据展示所具有的直观性。
涉及关系模型的二维表结构,再转变至 Transact - SQL 的特定查询语句,当中每一步步步都存有明晰的脉络。
实际操作时多写几条语句对比结果,理解会更深。
内心期望,于今日呈现的这般种种内容,能够助力你顺畅地跨出 Sybase 数据库配置的起始第一步。
Comments NOTHING