
//支持 lambda 函数接口
import java.util.function.Consumer;
public interface Iterable {
//iterator 方法
Iterator iterator;
defaultvoidforEach(Consumer action) {
Objects.requireNon(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator spliterator {
return Spliterators.spliteratorUnknownSize(iterator, 0);
}
}
咱们直接聊个实战问题。
package java.util;
import java.util.function.Predicate;
import java.util.stream.Stream;
import java.util.stream.StreamSupport;
public interface Collection extends Iterable {
intsize;
booleanisEmpty;
booleancontains(Object o);
Iterator iterator;
Object toArray;
booleanadd(E e);
booleanremove(Object o);
booleancontainsAll(Collection c);
booleanremoveAll(Collection c);
defaultbooleanremoveIf(Predicate filter) {
Objects.requireNon(filter);
boolean removed = false;
final Iterator each = iterator;
while (each.hasNext) {
if (filter.test(each.next)) {
each.remove;
removed = true;
}
}
return removed;
}
booleanretainAll(Collection c);
voidclear;
inthashCode;
@Override
default Spliterator spliterator {
return Spliterators.spliterator(this, 0);
}
default Stream stream {
return StreamSupport.stream(spliterator, false);
}
default Stream parallelStream {
return StreamSupport.stream(spliterator, true);
}
}
package java.util;
import java.util.function.UnaryOperator;
public interface List extends Collection {
T toArray(T[] a);
booleanaddAll(Collection c);
booleanaddAll(int index, Collection c);
defaultvoidreplaceAll(UnaryOperator operator) {
Objects.requireNon(operator);
final ListIterator li = this.listIterator;
while (li.hasNext) {
li.set(operator.apply(li.next));
}
}
defaultvoidsort(Comparator c) {
Object a = this.toArray;
Arrays.sort(a, (Comparator) c);
ListIterator i = this.listIterator;
for (Object e : a) {
i.next;
i.set((E) e);
}
}
booleanequals(Object o);
E get(int index);
E set(int index, E element);
voidadd(int index, E element);
intindexOf(Object o);
intlastIndexOf(Object o);
ListIterator listIterator;
List subList(int fromIndex, int toIndex);
@Override
default Spliterator spliterator {
return Spliterators.spliterator(this, Spliterator.ORDERED);
}
}
那你是否真的透彻理解了 HashMap 的 containsValue 方法呢?我曾带领过众多学员,他们一开始就误以为它能够如同 containsKey 那般高效,结果导致线上服务直接陷入卡死状态。
private static final Object EMPTY_ELEMENTDATA = {};
private static final Object DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}
//真正存放元素的数组
transient Object elementData; // non-private to simplify nested class access
private int size;
publicArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
publicArrayList {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
今天我就手把手带你把这个坑填平。
publicbooleanadd(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
privatestaticintcalculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//DEFAULT_CAPACITY 是 10
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
int newCapacity = oldCapacity + (oldCapacity >> 1);
containsValue 的底层原理你必须知道
privatevoidgrow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
publicstaticnativevoidarraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
p = (int *)malloc(len*sizeof(int));
先上最简可运行代码,让你立马看到效果:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject;
// Write out size as capacity for behavioural compatibility with clone
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException;
}
}
/**
* Reconstitute the ArrayList instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject;
// Read in capacity
s.readInt; // ignored
if (size > 0) {
// be like clone, allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess.checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject;
}
}
}
protected transient int modCount = 0;
// 运行环境:JDK 8+ import java.util.HashMap; public class ContainsValueDemo { public static void main(String[] args) { HashMap map = new HashMap(); map.put("name", "张三"); map.put("age", "25"); // 检查 value 是否存在 boolean exists = map.containsValue("张三"); System.out.println("value '张三' 存在吗?" + exists); // 输出 true // 检查不存在的 value boolean notExists = map.containsValue("李四"); System.out.println("value '李四' 存在吗?" + notExists); // 输出 false } }transient Node first;
/**
* Pointer to last node.
* Invariant: (first == && last == ) ||
* (last.next == && last.item != )
*/
transient Node last;private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}transient int size = 0;
transient Node first;
transient Node last;
publicLinkedList {
}/**
* Links e as first element. 头插法
*/
privatevoidlinkFirst(E e) {
final Node f = first;
final Node newNode = new Node(, e, f);
first = newNode;
if (f == )
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
/**
* Links e as last element. 尾插法
*/
voidlinkLast(E e) {
final Node l = last;
final Node newNode = new Node(l, e, );
last = newNode;
if (l == )
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}public E get(int index) {
checkElementIndex(index);
return node(index).item;
}Node node(int index) {
// assert isElementIndex(index);
//判断 index 更靠近头部还是尾部
if (index > 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}public E set(int index, E element) {
checkElementIndex(index);
Node x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}这个方法的核心坑在哪? 看源码你就明白了。
publicbooleanadd(E e) {
linkLast(e);
return true;
}//存放元素的数组
protected Object elementData;
//有效元素数量,小于等于数组长度
protected int elementCount;
//容量增加量,和扩容相关
protected int capacityIncrement;containsValue 和 containsKey 全然不一样——它并未采用哈希索引,而是径直通过暴力方式去遍历底层的 table 数组以及每个 bin 之上的链表或者红黑树。
privatevoidgrow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//扩容大小
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}public synchronized E remove(int index) {
modCount++;
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
int numMoved = elementCount - index - 1;
if (numMoved > 0)
//复制数组,假设数组移除了中间某元素,后边有效值前移 1 位
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//引用 ,gc 会处理
elementData[--elementCount] = ; // Let gc do its work
return oldValue;
}
时间复杂度是 O(n),n 是 HashMap 的大小。
Stack strings = new Stack;
strings.push("aaa");
strings.push("bbb");
strings.push("ccc");
System.err.println(strings.pop);/**
* Stack 源码(Jdk8)
*/
public
class Stack extends Vector {
publicStack {
}
//入栈,使用的是 Vector 的 addElement 方法。
public E push(E item) {
addElement(item);
return item;
}
//出栈,找到数组最后一个元素,移除并返回。
public synchronized E pop {
E obj;
int len = size;
obj = peek;
removeElementAt(len - 1);
return obj;
}
public synchronized E peek {
int len = size;
if (len == 0)
throw new EmptyStackException;
return elementAt(len - 1);
}
publicbooleanempty {
return size == 0;
}
publicsynchronizedintsearch(Object o) {
int i = lastIndexOf(o);
if (i >= 0) {
return size - i;
}
return -1;
}
private static final long serialVersionUID = 1224463164541339165L;
}我带学员踩过的真实坑
package java.util;
public interface Queue extends Collection {
//集合中插入元素
booleanadd(E e);
//队列中插入元素
booleanoffer(E e);
//移除元素,当集合为空,抛出异常
E remove;
//移除队列头部元素并返回,如果为空,返回
E poll;
//查询集合第一个元素,如果为空,抛出异常
E element;
//查询队列中第一个元素,如果为空,返回
E peek;
}
有一位学员,处于电商项目当中,运用 containsValue,去对用户所输入的商品编码,进行是否重复的校验。
package java.util;
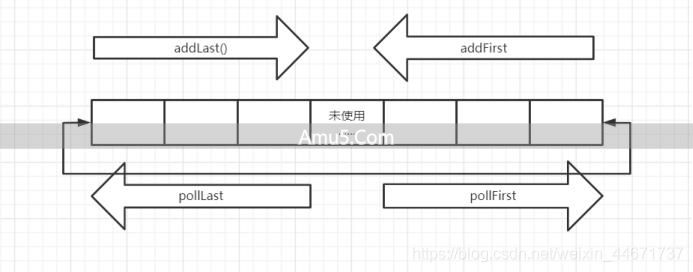
public interface Deque extends Queue {
//deque 的操作方法
voidaddFirst(E e);
voidaddLast(E e);
booleanofferFirst(E e);
booleanofferLast(E e);
E removeFirst;
E removeLast;
E pollFirst;
E pollLast;
E getFirst;
E getLast;
E peekFirst;
E peekLast;
booleanremoveFirstOccurrence(Object o);
booleanremoveLastOccurrence(Object o);
// *** Queue methods ***
booleanadd(E e);
booleanoffer(E e);
E remove;
E poll;
E element;
E peek;
// 省略一堆 stack 接口方法和 collection 接口方法
}商品表才 10 万条数据,本来挺快的。
PriorityQueue queue = new PriorityQueue;
queue.add(20);queue.add(14);queue.add(21);queue.add(8);queue.add(9);
queue.add(11);queue.add(13);queue.add(10);queue.add(12);queue.add(15);
while (queue.size>0){
Integer poll = queue.poll;
System.err.print(poll+"->");
}
结果双 11 期间 QPS 一上来,CPU 直接飙到 100%。
// 必须实现 Comparable 方法,想 String,数值本身即可比较
private static class Test implements Comparable{
private int a;
publicTest(int a) {
this.a = a;
}
publicintgetA {
return a;
}
publicvoidsetA(int a) {
this.a = a;
}
@Override
public String toString {
return "Test{" +
"a=" + a +
'}';
}
@Override
public int compareTo(Test o) {
return 0;
}
}
publicstaticvoidmain(String[] args) {
PriorityQueue queue = new PriorityQueue;
queue.add(new Test(20));queue.add(new Test(14));queue.add(new Test(21));queue.add(new Test(8));queue.add(new Test(9));
queue.add(new Test(11));queue.add(new Test(13));queue.add(new Test(10));queue.add(new Test(12));queue.add(new Test(15));
while (queue.size>0){
Test poll = queue.poll;
System.err.print(poll+"->");
}
}/**
* 默认容量大小,数组大小
*/
private static final int DEFAULT_INITIAL_CAPACITY = 11;
/**
* 存放元素的数组
*/
transient Object queue; // non-private to simplify nested class access
/**
* 队列中存放了多少元素
*/
private int size = 0;
/**
* 自定义的比较规则,有该规则时优先使用,否则使用元素实现的 Comparable 接口方法。
*/
private final Comparator comparator;
/**
* 队列修改次数,每次存取都算一次修改
*/
transient int modCount = 0; // non-private to simplify nested class access为啥?
public boolean offer(E e) {
if (e == )
throw new PointerException;
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
//i=size,当 queue 为空的时候
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}private void siftUp(int k, E x) {
if (comparator != )
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}privatevoidsiftUpComparable(int k, E x) {
Comparable key = (Comparable) x;
while (k > 0) {
//为什么-1, 思考数组位置 0,1,2。0 是 1 和 2 的父节点
int parent = (k - 1) >>> 1;
//父节点
Object e = queue[parent];
//当传入的新节点大于父节点则不做处理,否则二者交换
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
由于他每一次请求均需对整个 HashMap 的 value 集合展开遍历,10 万个 value 在每个请求时都要进行一次遍历,而 1000 个并发就等同于 1 亿次遍历。
public E poll {
if (size == 0)
return ;
int s = --size;
modCount++;
E result = (E) queue[0];
//s = --size,即原来数组的最后一个元素
E x = (E) queue[s];
queue[s] = ;
if (s != 0)
siftDown(0, x);
return result;
}privatevoidsiftDownComparable(int k, E x) {
Comparable key = (Comparable)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
//c 和 right 是 parent 的两个子节点,找出小的那个成为新的 c。
((Comparable) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
//小的变成了新的父节点
queue[k] = c;
k = child;
}
queue[k] = key;
}
正确的解决办法是:要是存在需要借助 value 对 key 进行高频查找的情况,那么你理应去维护一个双向映射,举例来说,可以使用 Google 的 BiMap,或者自行另外弄出一个 HashMap 反向索引。
ArrayDeque deque = new ArrayDeque;
deque.offer("aaa");
deque.offer("bbb");
deque.offer("ccc");
deque.offer("ddd");
//peek 方法只获取不移除
System.err.println(deque.peekFirst);
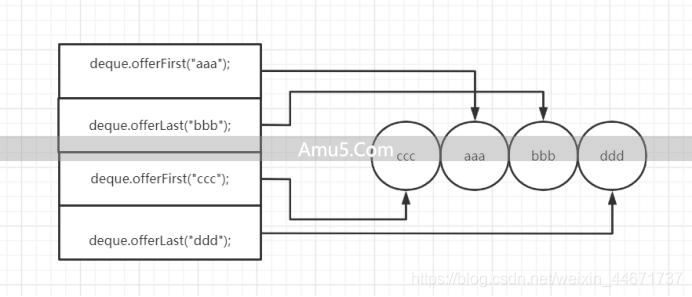
System.err.println(deque.peekLast);ArrayDeque deque = new ArrayDeque;
deque.offerFirst("aaa");
deque.offerLast("bbb");
deque.offerFirst("ccc");
deque.offerLast("ddd");
String a;
while((a = deque.pollLast)!=){
System.err.print(a+"->");
}代码示例:
//具体存放元素的数组,数组大小一定是 2 的幂次方
transient Object elements; // non-private to
//队列头索引
transient int head;
//队列尾索引
transient int tail;
//默认的最小初始化容量,即传入的容量小于 8 容量为 8,而默认容量是 16
private static final int MIN_INITIAL_CAPACITY = 8;privatestaticintcalculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
return initialCapacity;
}// 企业级优化版:维护反向索引 public class BiDirectionalMap { private final HashMap forward = new HashMap(); private final HashMap reverse = new HashMap(); public void put(K key, V value) { forward.put(key, value); reverse.put(value, key); } public boolean containsValue(V value) { return reverse.containsKey(value); // O(1)操作! } public K getKeyByValue(V value) { return reverse.get(value); } }
public void addFirst(E e) {
if (e == )
throw new PointerException;
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity;
}head = (head - 1) & (elements.length - 1)head = head-1>=0?head-1:elements.length-1public void addLast(E e) {
if (e == )
throw new PointerException;
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity;
}(tail = (tail + 1) & (elements.length - 1))package java.util;
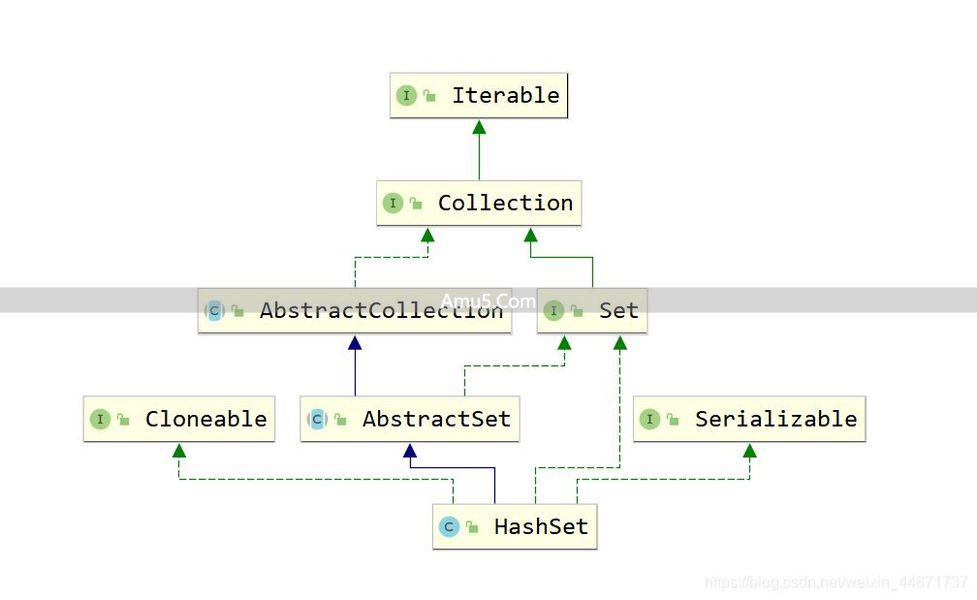
public interface Set extends Collection {
// Query Operations
intsize;
booleanisEmpty;
Object toArray;
T toArray(T[] a);
// Modification Operations
booleanadd(E e);
booleanremove(Object o);
booleancontainsAll(Collection c);
booleanaddAll(Collection c);
booleanretainAll(Collection c);
booleanremoveAll(Collection c);
voidclear;
booleanequals(Object o);
inthashCode;
//此处和 Collection 接口由区别
Spliterator spliterator {
return Spliterators.spliterator(this, Spliterator.DISTINCT);
}
}什么时候可以用 containsValue?
public class HashSet
extends AbstractSet
implements Set, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap map;
private static final Object PRESENT = new Object;
publicHashSet {
map = new HashMap;
}
publicHashSet(Collection c) {
map = new HashMap(Math.max((int) (c.size/.75f) + 1, 16));
addAll(c);
}
publicHashSet(int initialCapacity, float loadFactor) {
map = new HashMap(initialCapacity, loadFactor);
}
publicHashSet(int initialCapacity) {
map = new HashMap(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap(initialCapacity, loadFactor);
}
public Iterator iterator {
return map.keySet.iterator;
}
publicintsize {
return map.size;
}
public boolean isEmpty {
return map.isEmpty;
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
publicvoidclear {
map.clear;
}
}说实话,数据量小于 100 且调用频率极低的场景你随便用。
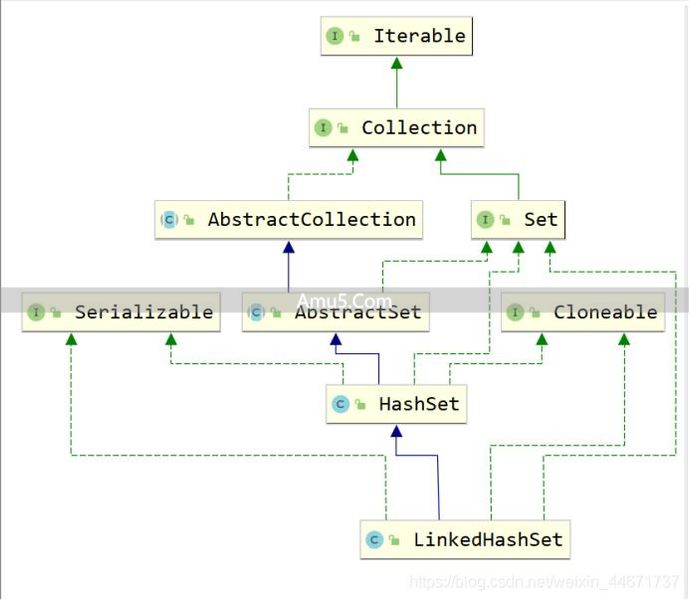
package java.util;
public class LinkedHashSet
extends HashSet
implements Set, Cloneable, java.io.Serializable {
private static final long serialVersionUID = -2851667679971038690L;
publicLinkedHashSet(int initialCapacity, float loadFactor) {
//调用 HashSet 的构造方法
super(initialCapacity, loadFactor, true);
}
publicLinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
publicLinkedHashSet {
super(16, .75f, true);
}
publicLinkedHashSet(Collection c) {
super(Math.max(2*c.size, 11), .75f, true);
addAll(c);
}
@Override
public Spliterator spliterator {
return Spliterators.spliterator(this, Spliterator.DISTINCT |
Spliterator.ORDERED);
}
}HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap(initialCapacity, loadFactor);
}
比如后台配置初始化时的校验、单元测试里的断言。
package java.util;
import java.util.function.BiConsumer;
import java.util.function.BiFunction;
import java.util.function.Function;
import java.io.Serializable;
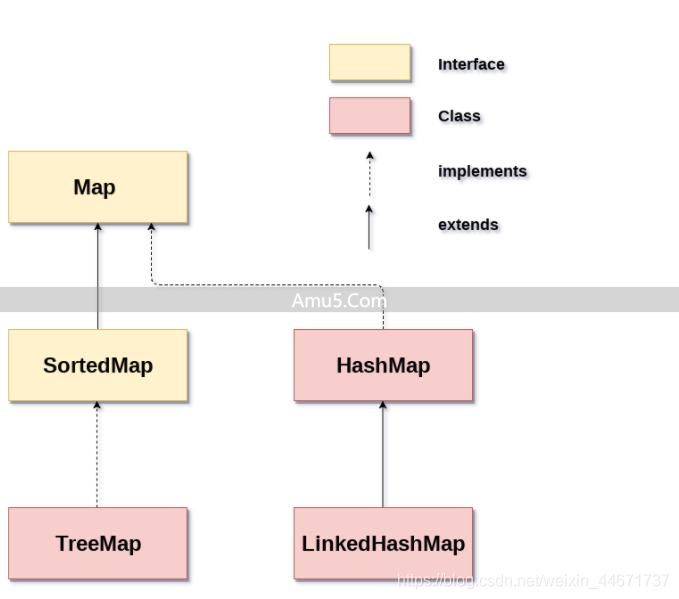
public interface Map {
// Query Operations
int size;
boolean isEmpty;
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
// Modification Operations
V put(K key, V value);
V remove(Object key);
// Bulk Operations
void putAll(Map m);
void clear;
Set keySet;
Collection values;
Set<Map.Entry> entrySet;
interface Entry {
K getKey;
V getValue;
V setValue(V value);
boolean equals(Object o);
int hashCode;
public static <K extends Comparable, V> Comparator<Map.Entry> comparingByKey {
return (Comparator<Map.Entry> & Serializable)
(c1, c2) -> c1.getKey.compareTo(c2.getKey);
}
public static <K, V extends Comparable> Comparator<Map.Entry> comparingByValue {
return (Comparator<Map.Entry> & Serializable)
(c1, c2) -> c1.getValue.compareTo(c2.getValue);
}
public static Comparator<Map.Entry> comparingByKey(Comparator cmp) {
Objects.requireNon(cmp);
return (Comparator<Map.Entry> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey, c2.getKey);
}
public static Comparator<Map.Entry> comparingByValue(Comparator cmp) {
Objects.requireNon(cmp);
return (Comparator<Map.Entry> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue, c2.getValue);
}
}
// Comparison and hashing
boolean equals(Object o);
int hashCode;
default V getOrDefault(Object key, V defaultValue) {
V v;
return (((v = get(key)) != ) || containsKey(key))
? v
: defaultValue;
}
default void forEach(BiConsumer action) {
Objects.requireNon(action);
for (Map.Entry entry : entrySet) {
K k;
V v;
try {
k = entry.getKey;
v = entry.getValue;
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
default void replaceAll(BiFunction function) {
Objects.requireNon(function);
for (Map.Entry entry : entrySet) {
K k;
V v;
try {
k = entry.getKey;
v = entry.getValue;
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
// ise thrown from function is not a cme.
v = function.apply(k, v);
try {
entry.setValue(v);
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
}
}
default V putIfAbsent(K key, V value) {
V v = get(key);
if (v == ) {
v = put(key, value);
}
return v;
}
default boolean remove(Object key, Object value) {
Object curValue = get(key);
if (!Objects.equals(curValue, value) ||
(curValue == && !containsKey(key))) {
return false;
}
remove(key);
return true;
}
default boolean replace(K key, V oldValue, V newValue) {
Object curValue = get(key);
if (!Objects.equals(curValue, oldValue) ||
(curValue == && !containsKey(key))) {
return false;
}
put(key, newValue);
return true;
}
default V replace(K key, V value) {
V curValue;
if (((curValue = get(key)) != ) || containsKey(key)) {
curValue = put(key, value);
}
return curValue;
}
default V computeIfAbsent(K key,
Function mappingFunction) {
Objects.requireNon(mappingFunction);
V v;
if ((v = get(key)) == ) {
V newValue;
if ((newValue = mappingFunction.apply(key)) != ) {
put(key, newValue);
return newValue;
}
}
return v;
}
default V computeIfPresent(K key,
BiFunction remappingFunction) {
Objects.requireNon(remappingFunction);
V oldValue;
if ((oldValue = get(key)) != ) {
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != ) {
put(key, newValue);
return newValue;
} else {
remove(key);
return ;
}
} else {
return ;
}
}
default V compute(K key,
BiFunction remappingFunction) {
Objects.requireNon(remappingFunction);
V oldValue = get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue == ) {
// delete mapping
if (oldValue != || containsKey(key)) {
// something to remove
remove(key);
return ;
} else {
// nothing to do. Leave things as they were.
return ;
}
} else {
// add or replace old mapping
put(key, newValue);
return newValue;
}
}
default V merge(K key, V value,
BiFunction remappingFunction) {
Objects.requireNon(remappingFunction);
Objects.requireNon(value);
V oldValue = get(key);
V newValue = (oldValue == ) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == ) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}
}
但一旦数据量过千或者放在请求链路里,那就是定时炸弹。
transient Node table;避坑指南:
//是 hashMap 的最小容量 16,容量就是数组的大小也就是变量,transient Node table。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大数量,该数组最大值为 2^31 一次方。
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的加载因子,如果构造的时候不传则为 0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//一个位置里存放的节点转化成树的阈值,也就是 8,比如数组里有一个 node,这个
// node 链表的长度达到该值才会转化为红黑树。
static final int TREEIFY_THRESHOLD = 8;
//当一个反树化的阈值,当这个 node 长度减少到该值就会从树转化成链表
static final int UNTREEIFY_THRESHOLD = 6;
//满足节点变成树的另一个条件,就是存放 node 的数组长度要达到 64
static final int MIN_TREEIFY_CAPACITY = 64;
//具体存放数据的数组
transient Node table;
//entrySet,一个存放 k-v 缓冲区
transient Set<Map.Entry> entrySet;
//size 是指 hashMap 中存放了多少个键值对
transient int size;
//对 map 的修改次数
transient int modCount;
//加载因子
final float loadFactor;//只有容量,initialCapacity
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(Map m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
final void putMapEntries(Map m, boolean evict) {
int s = m.size;
if (s > 0) {
if (table == ) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize;
for (Map.Entry e : m.entrySet) {
K key = e.getKey;
V value = e.getValue;
putVal(hash(key), key, value, false, evict);
}
}
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0) // 容量不能为负数
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//当容量大于 2^31 就取最大值 1<<31;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//当前数组 table 的大小,一定是是 2 的幂次方
// tableSizeFor 保证了数组一定是是 2 的幂次方,是大于 initialCapacity 最结进的值。
this.threshold = tableSizeFor(initialCapacity);
}千万不要在循环之中去调用 containsValue,那样的话复杂度会直接提升到 O(n²)。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n = MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node tab; Node p; int n, i;
if ((tab = table) == || (n = tab.length) == 0)
n = (tab = resize).length;
//当 hash 到的位置,该位置为的时候,存放一个新 node 放入
// 这儿 p 赋值成了 table 该位置的 node 值
if ((p = tab[i = (n - 1) & hash]) == )
tab[i] = newNode(hash, key, value, );
else {
Node e; K k;
//该位置第一个就是查找到的值,将 p 赋给 e
if (p.hash == hash &&
((k = p.key) == key || (key != && key.equals(k))))
e = p;
//如果是红黑树,调用红黑树的 putTreeVal 方法
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
//是链表,遍历,注意 e = p.next 这个一直将下一节点赋值给 e,直到尾部,注意开头是++binCount
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == ) {
p.next = newNode(hash, key, value, );
//当链表长度大于等于 7,插入第 8 位,树化
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != && key.equals(k))))
break;
p = e;
}
}
if (e != ) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == )
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize;
afterNodeInsertion(evict);
return ;
}final Node getNode(int hash, Object key) {
Node tab; Node first, e; int n; K k;
//先判断表不为空
if ((tab = table) != && (n = tab.length) > 0 &&
//这一行是找到要查询的 Key 在 table 中的位置,table 是存放 HashMap 中每一个 Node 的数组。
(first = tab[(n - 1) & hash]) != ) {
//Node 可能是一个链表或者树,先判断根节点是否是要查询的 key,就是根节点,方便后续遍历 Node 写法并且
//对于只有根节点的 Node 直接判断
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != && key.equals(k))))
return first;
//有子节点
if ((e = first.next) != ) {
//红黑树查找
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
do {
//链表查找
if (e.hash == hash &&
((k = e.key) == key || (key != && key.equals(k))))
return e;
}
//遍历链表,当链表后续为则推出循环
while ((e = e.next) != );
}
}
return ;
}一旦 value 属于自定义对象范畴,那就得记着去重写 equals(),不然的话,始终都寻觅不到。
public abstract
class Dictionary {
publicDictionary {
}
publicabstractintsize;
publicabstractbooleanisEmpty;
public abstract Enumeration keys;
public abstract Enumeration elements;
public abstract V get(Object key);
public abstract V put(K key, V value);
public abstract V remove(Object key);
}位于源码之中的,以(V v : values)形式呈现的,那便是进行遍历的操作,不管运用何种优化的手段,都是没办法挽救的。
//throws PointerException if the {@code key} is {@code }./**
* The hash table data.
* 真正存放数据的数组
*/
private transient Entry table;
/**
* The total number of entries in the hash table.
*/
private transient int count;
/**
* The table is rehashed when its size exceeds this threshold. (The
* value of this field is (int)(capacity * loadFactor).)
* 重新 hash 的阈值
* @serial
*/
private int threshold;
/**
* The load factor for the hashtable.
* @serial
*/
private float loadFactor;final int hash;
final K key;
V value;
Entry next;public synchronized V put(K key, V value) {
// Make sure the value is not
if (value == ) {
throw new PointerException;
}
// Makes sure the key is not already in the hashtable.
Entry tab = table;
int hash = key.hashCode;
//在数组中的位置 0x7fffffff 是 31 位二进制 1
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry entry = (Entry)tab[index];
for(; entry != ; entry = entry.next) {
//如果遍历链表找到了则替换旧值并返回
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return ;
}给到你一个真实的建议,最后,当面试官询问你 HashMap 的 containsValue 的时间复杂度时,你若回答 O(n),仅仅只能算是及格。
private void addEntry(int hash, K key, V value, int index) {
Entry tab = table;
//如果扩容需要重新计算 hash,所以 index 和 table 都会被修改
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash;
tab = table;
hash = key.hashCode;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry e = (Entry) tab[index];
//插入新元素
tab[index] = new Entry(hash, key, value, e);
count++;
modCount++;
}tab[index] = new Entry(hash, key, value, e);@SuppressWarnings("unchecked")
public synchronized V get(Object key) {
Entry tab = table;
int hash = key.hashCode;
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry e = tab[index] ; e != ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return ;
}在能够清晰且准确地表述出“它会遍历 table 并逐个 equals 比较 value,建议小数据量使用或改用反向索引”的情形下,才可以被认定为是真正懂得源码的人。
上一篇文章 下一篇文章利德理疗仪:老年人家庭用的生物电经络治疗仪
血糖不稳被药物副作用折磨?这款糖尿病治疗仪来帮您





Comments NOTHING