
Linux环境下Elasticsearch分布式集群运维实战
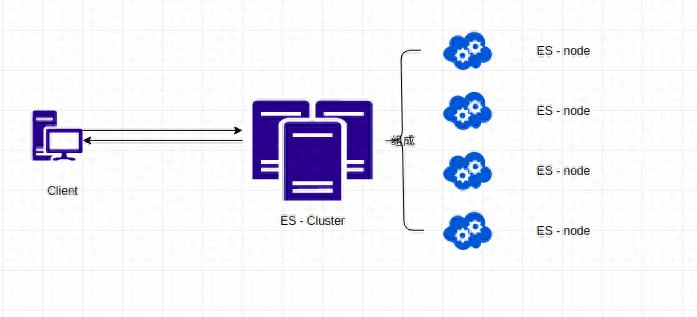
在Linux服务器上部署Elasticsearch分布式集群,是构建企业级搜索服务的核心环节。
本文将围绕CentOS 7.9系统环境,详解从零搭建Elasticsearch集群的完整流程,涵盖域名解析配置、Docker容器化部署、服务器资源规划等实操内容。
一、服务器环境准备
购买云服务器建议选择4核8GB以上配置,推荐使用腾讯云S5或阿里云g6系列实例。
操作系统统一采用CentOS 7.9 64位,所有节点需配置内网互通。
假设规划三节点集群:
node1:172.16.0.1(主节点候选)
node2:172.16.0.2(数据节点)
node3:172.16.0.3(数据节点)
登录服务器后执行系统优化:
# 修改系统限制
echo " soft nofile 655360" >> /etc/security/limits.conf
echo " hard nofile 655360" >> /etc/security/limits.conf
echo " soft nproc 4096" >> /etc/security/limits.conf
echo " hard nproc 4096" >> /etc/security/limits.conf
# 禁用swap
echo "vm.swappiness=0" >> /etc/sysctl.conf
sysctl -p
二、D方式部署Elasticsearch
采用Docker容器化部署可简化版本管理。
首先安装Docker环境:
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
systemctl enable docker && systemctl start docker
拉取官方镜像(以7.17.15版本为例):
docker pull elasticsearch:7.17.15
创建挂载目录和配置文件:
mkdir -p /data/es/{config,data,logs}
chmod 777 /data/es/data
cat > /data/es/config/elasticsearch.yml << EOF
cluster.name: production-es
node.name: node-1
path.data: /usr/share/elasticsearch/data
path.logs: /usr/share/elasticsearch/logs
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["172.16.0.1", "172.16.0.2", "172.16.0.3"]
cluster.initial_master_nodes: ["node-1"]
EOF
启动容器:
docker run -d
--name es-node1
--restart=always
-p 9200:9200
-p 9300:9300
-v /data/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
-v /data/es/data:/usr/share/elasticsearch/data
-v /data/es/logs:/usr/share/elasticsearch/logs
-e "ES_JAVA_OPTS=-Xms4g -Xmx4g"
elasticsearch:7.17.15

三、域名解析与Nginx代理
购买域名后(如search.example.com),在云解析控制台添加A记录指向任意节点公网IP。
为统一访问入口,部署Nginx做负载均衡:
# 安装Nginx
yum install nginx -y
# 配置反向代理
cat > /etc/nginx/conf.d/es.conf << EOF
upstream es_backend {
server 172.16.0.1:9200 max_fails=3 fail_timeout=30s;
server 172.16.0.2:9200 max_fails=3 fail_timeout=30s;
server 172.16.0.3:9200 max_fails=3 fail_timeout=30s;
}
server {
listen 80;
server_name search.example.com;
location / {
proxy_pass http://es_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
EOF
nginx -t && systemctl restart nginx
四、集群健康状态验证
通过curl命令检查集群状态:
curl -X GET "http://search.example.com/_cluster/health?pretty"
正常返回应显示"status" : "green",且"number_of_nodes" : 3。
若为yellow状态,说明存在未分配副本分片,需检查磁盘空间或调整副本数。
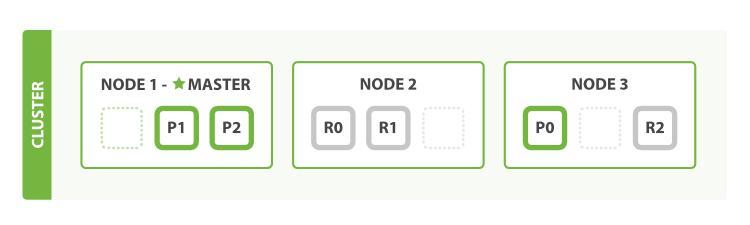
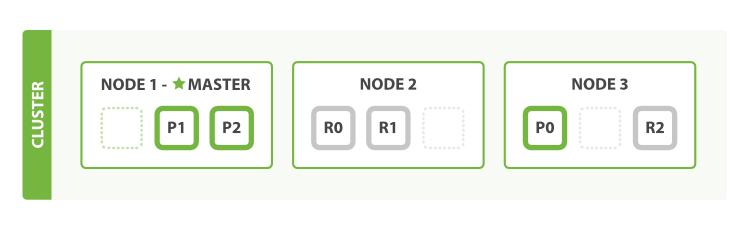
五、分片规划与性能调优
根据数据量评估分片配置。
假设单日日志量50GB,保留30天共1.5TB数据,按单个分片30GB计算:
# 创建索引时指定分片数
curl -X PUT "search.example.com/logs-2026.02.28" -H 'Content-Type: application/json' -d'
{
"settings": {
"number_of_shards": 50,
"number_of_replicas": 1
}
}'
监控磁盘使用率,设置告警阈值:
# 查看磁盘空间
df -h | grep /dev/vda1
# 配置ES磁盘水位线
curl -X PUT "search.example.com/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"transient": {
"cluster.routing.allocation.disk.watermark.low": "85%",
"cluster.routing.allocation.disk.watermark.high": "90%",
"cluster.routing.allocation.disk.watermark.flood_stage": "95%"
}
}'
number_of_shards 主分片数
number_of_replicas 副本分片数
{
"my_index": {
"settings": {
"index": {
"number_of_shards": "8",
"number_of_replicas": "1"
}
}
}
}
六、生产环境注意事项
1. 节点角色分离:通过配置node.roles精确指定主节点、数据节点、协调节点角色
2. JVM堆内存设置:不超过物理内存50%,且最大不超过32GB
3. 索引生命周期管理:使用ILM策略自动rollover和删除过期索引
4. 安全加固:开启X-Pack认证,配置防火墙仅放行指定IP访问9200端口
通过以上步骤,即可在Linux服务器上完成企业级Elasticsearch集群的部署。
实际运维中需结合Prometheus+Grafana监控体系,实现集群状态的实时观测与预警。
Comments NOTHING