
上周一的下午时分,我们那有着编程导航功能的网站,突然间就出现了访问方面的故障情况,用户反馈页面持续地在转圈,并且没办法进行加载。
该项目是借助Spring Boot所构建的,它被部署于Docker容器当中,针对这类问题而言,常常会直接指向底层用以运维配置的薄弱之处。

今天便着手对这次事故展开复盘,深入学习Linux服务器方面的实操经验,深入探究Tomcat线程模型方面的实操见闻,深入钻研Docker容器资源限制事宜所涉及的实操心得,深入剖析云服务器配置内容里的实操诀窍。
事故现象:接口全线阻塞,健康检查也超时
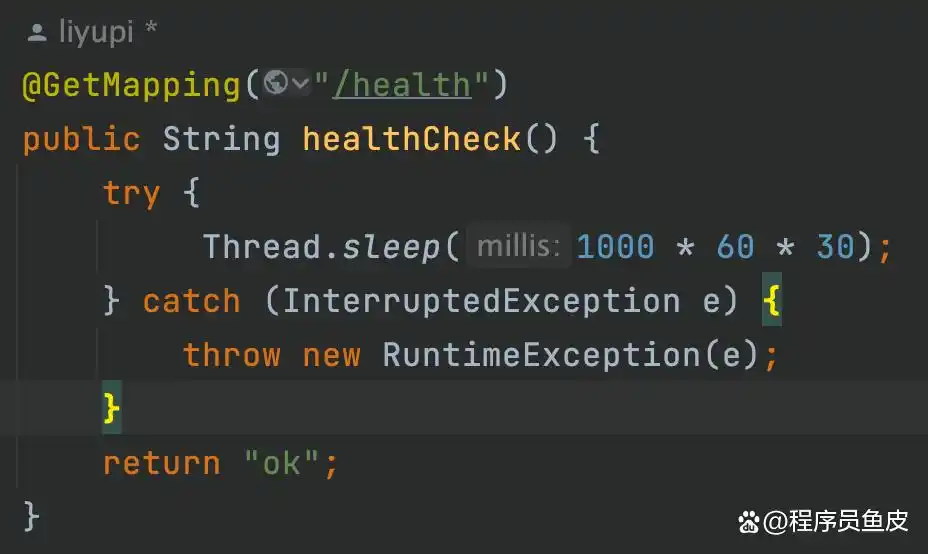
故障发生时,前端请求全部挂起,直至超时。
最诡异的是,连不查询数据库的健康检查接口也毫无响应。
这表明,问题存在于更深层次的Web服务器之处,或者是容器层面那里,相比于业务代码而言。
这是我们的后端服务,它被部署在了腾讯云轻量应用服务器之上,并且是以Docker容器化的方式来运行的,借助Portainer进行管理。
通常状况之下,容器平态设有监控以及扩容机制,然而在此一回,CPU占用并非处于高位,内存占用同样未达较高程度,却并未触发自动化的扩容操作。
这其实是个常见误区:CPU未占满,不代表应用线程池未占满。
深度排查:Linux服务器与Docker容器线程快照
第一时间进入Linux服务器,执行那组代码查看容器状态,确定服务还处于运行之中。
接着进入容器内部抓取线程快照:
docker exec -it /bin/bash
jstack -l > thread_dump.txt
退出容器后,将线程文件复制到宿主机分析:
docker cp :/path/to/thread_dump.txt ./thread_dump.txt
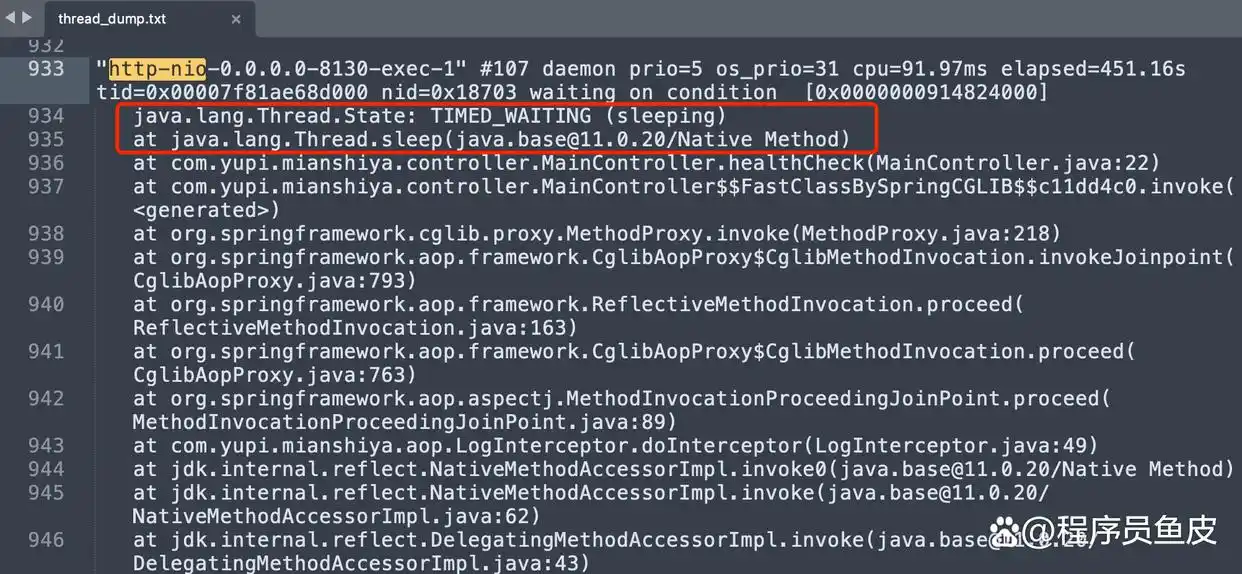
将文档开启,去寻觅那,http - nio,,,搜寻到结果以后,发觉每一个请求处理的线程所处的状态全都是,TIMED_WAITING,,,并且阻塞的关键点确切地指向同一个针对数据库的查询方法。
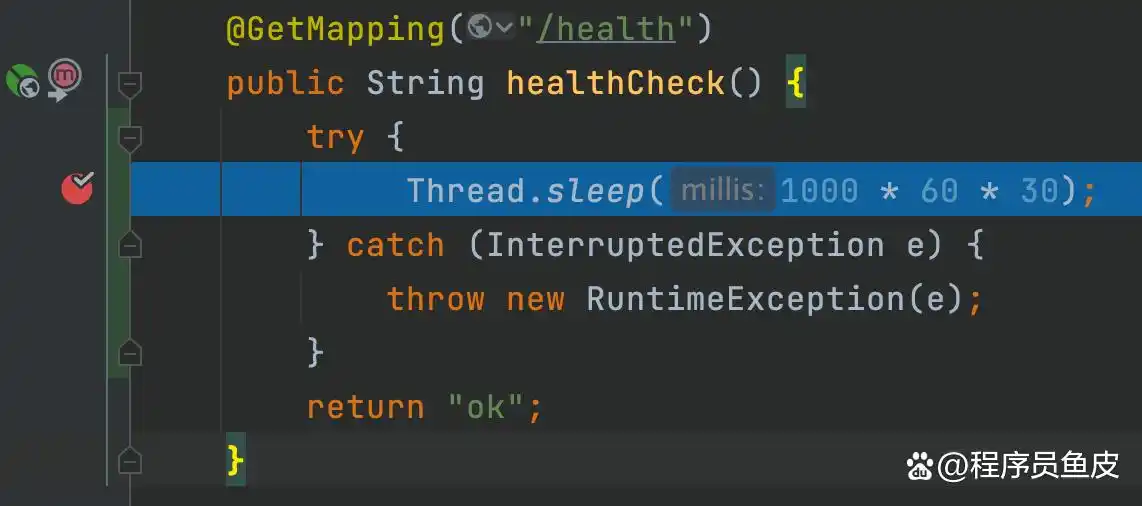
这便是典型的那种Tomcat线程池耗尽情况,Spring Boot内嵌的Tomcat其默认的最大线程数是200,在200个线程全部被慢查询给卡住之时,第201个请求就只能去排队了,就连健康检查接口也同样是如此这般。
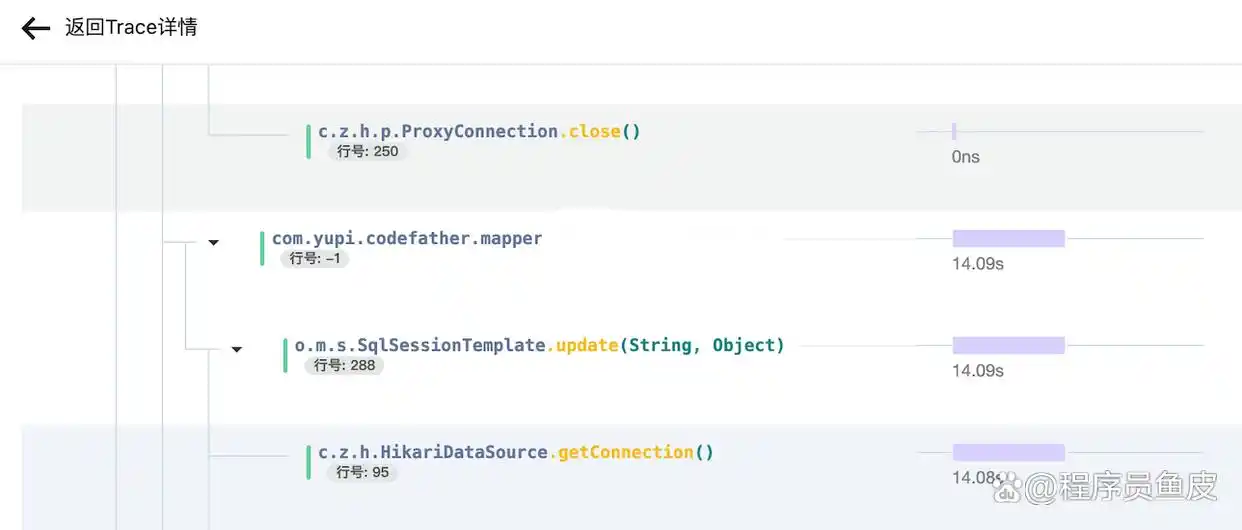
根源分析:慢SQL + 连接池配置不当

进一步追踪,慢SQL源于用户查询方法。
由于前边开展了短信召回活动致使大批用户蜂拥而至,然而此查询并未命中索引,执行起来耗费了数秒时间。
每次请求都会占用一个Tomcat线程去等待数据库给出返回,但是数据库连接池,这其中HikariCP默认的最大连接数是10,它也已经完全满了,这就使得后续的请求就得去排队。
这里暴露了典型的云服务器运维配置问题:
1. 数据库索引缺失:生产环境未对高频查询字段添加索引。
2. 存在这样一种情况,即连接池进行配置操作时,所设置的规模过小:具体表现为,作为连接池的HikariCP,其能够容纳支持的最大连接数量仅仅只有10个,然而这样的数目远远不能够满足支撑并发操作的需求,从而导致相应问题的出现。
3. Tomcat线程数和容器资源不相匹配:Docker容器所分配的CPU核心数存在限制,线程数要是过高就会反倒增加上下文切换。
解决方案:从Linux内核参数到应用配置的全面调优
1. 立即止损:重启与扩容
故障出现以后,最先借助docker restart 迅速让服务得以恢复,与此同时临时性增添容器实例的数量:
docker-compose up -d --scale app=3
2. 索引优化:根治慢SQL
于MySQL里头开展EXPLAIN去剖析慢查询,去向user_query表的有关字段加上联合索引:
ALTER TABLE user_query ADD INDEX idx_user_status (user_id, status);
3. 调整Tomcat与数据库连接池
更改application.yml,依据云服务器配置(2核4G)适度调整参数:
server:
tomcat:
max-threads: 100 # 根据CPU核心数调整,避免过多线程竞争
min-spare-threads: 20 # 保持常驻线程
accept-count: 50 # 等待队列长度
spring:
datasource:
hikari:
maximum-pool-size: 20 # 数据库连接池大小,不宜超过数据库max_connections
minimum-idle: 5
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000
4. Docker容器资源限制
于docker-compose.yml里确切明晰资源上限,以此避免容器去争抢宿主机资源:
services:
app:
image: your_app_image
deploy:
resources:
limits:
cpus: '1.0'
memory: 2G
reservations:
cpus: '0.5'
memory: 1G
5. Linux内核参数优化
于宿主机,在/etc/sysctl.conf里,对网络以及文件句柄限制作出调整:
# 增加文件句柄数
fs.file-max = 655350
# 优化TCP连接
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
# 生效
sysctl -p
预防措施:构建可观测的运维体系
1. 把SkyWalking或者Prometheus加上Grafana于Docker环境里开展部署,以此获得实时监控Tomcat线程数以及数据库连接池状态的效果,此即集成APM监控。
2. 慢查询日志,将MySQL慢查询日志予以开启,并且把阈值设置为long_query_time = 1。
3. 进行定期的压测:为了提前发现瓶颈,运用JMeter针对关键接口开展压力测试。
4. 就“自动化扩缩容”而言,要与容器平台相结合,去配置那基于请求数的HPA(Horizontal Pod Autoscaling)。
总结
这次事故再次印证了“线上无小事”。
从Linux服务器的各项参数,到Tomcat线程的具体模型,从数据库索引部分,到Docker容器资源的限定范围,每一个环节,都需要进行精细精细再精细的打磨。
要是健康检查接口被堵死了,那就得立刻dump线程快照,通常这样能直接找出Tomcat线程池的问题。
盼望着,此次复盘能够助力诸位,在云服务器配置方面,以及容器化部署方面,减少走那些不必要的曲折路径,切实地促使系统的健壮性得以真正提升。
Comments NOTHING