
在数据库领域当中,元数据管理常常被视作一种基础设施,然而实际上,它是数据仓库达成稳定运行、实现高效查询以及得以持续演进的“神经系统”。
对于将那犹如大厦一般的现代化的数据贮藏站比作一座图书馆而言,假定数据是书籍的情况下那元数据就是用来对该书检索条目来进行安排的,同时也是那书籍被借阅时候记录凭证、摆放位置地图与分布描绘。
没有元数据,数据仓库便只是一堆无序文件的堆砌,这是一种没有组织状的情况这样的堆砌无法支撑起复杂的商业智能分析,更无法承担起决策支持系统的作用。
元数据在数据库层面的具象化
于数据库技术的视角而言,元数据并非单纯只是抽象的那种“说明书”,它直接判定了数据库的性能呈现景象状况以及可维护性情况。
1. 数据字典与系统表:
在Oracle里,或是MySQL之中,再或者PostgreSQL内,元数据被存储于特定的系统表,又或者信息模式(Information Schema)那里。
比如说,TABLES这个表,它记录着所有表的存储引擎,还有行数,以及平均行长度;COLUMNS这个表呢,记载着字段的数据类型,还有字符集,另外还有是否为空这一情况。
这些元数据是数据库优化器生成执行计划的基础。
在执行一条 SELECT 查询之际,优化器会即刻读取这些元数据,去判断究竟是进行全表扫描还是走索引,而这直接对 SQL 的响应时间产生关联。
2. 索引元数据与性能优化:
查询性能提升的关键在于索引,就凭 DBA(数据库管理员)能进行调优,那索引自身的元数据(像索引类型、索引列的选择性这些)就是依据。
比如,于SQL Server里头,经由查询sys.indexes以及sys.dm_db_index_usage_stats,数据库管理员能够清楚明晰地瞧见哪些索引被频繁加以使用,哪些是从来都未曾被用过的冗余索引。
通过运用这些元数据,能够精确地施行索引的“瘦身”以及“加固”操作。于此同时,提升查询流程的速度,并且降低数据写入阶段的维护方面的开销。
围绕元数据的 SQL 操作实战
日常对数据仓库开展运维之际,明晰元数据的查找窍门,可显著提高工作效能。
场景一:批量生成清理脚本
倘若我们有需求,要去删除某一个业务库之内,全部是以 2020_ 作为开头的临时表。
要是通过手去一条一条进行编写那种叫做 DROP TABLE 的语句,不仅仅会话费很长的时间,而且还蛮容易出现出差错这种情况的。
通过查询元数据表,可以一键生成 SQL:
MySQL 示例
SELECT CONCAT('DROP TABLE ', table_name, ';') AS drop_statement
FROM information_schema.tables
WHERE table_schema = 'temp_db' AND table_name LIKE '2020_%';
这样,数据库直接输出清理脚本,既规范又安全。
场景二:字段变更的依赖分析
在着手开展数据库结构变更这一行为(此变更涵盖删除一个字段这种情况)之前,务必要保证不存在存储过程或者视图在对它形成依赖性。
借助PostgreSQL的 pg_depend 系统表得以迅速定位全部依赖对象防止因任意修改元数据致使的生产事故。
元数据驱动的性能优化与运维
元数据管理,其直接服务对象为性能优化,它同时还是用于衡量数据仓库健康度的一种晴雨表。
1. 统计信息与执行计划
数据库中的统计信息是元数据的一种动态形式。
在Oracle里头,过于陈旧的统计信息,会致使优化器作出错误的判定,进而挑选错误的索引。
所以,定期去收集统计方面的信息,像 DBMS_STATS.GATHER_TABLE_STATS 这样的,这对于数据库管理员来说,是必须要修习的课程。
凭借对比历史统计信息所产生的改变局面,能够对 SQL 执行性能的衰减趋向予以预测,进而预先开展干预行为。
2. 数据生命周期管理
在大型数据仓库中,冷热数据分离是降低成本的关键。
由元数据记录当中的“最后访问时间”,以及“数据分区大小”,能够去制定具备智能特性的数据归档策略。
又如,于 Hive 数据仓库范畴内,借助元存储这般的方式,去查询到底哪些分区在过去的整整一年当中都未曾被查询过,进而能够把那些分区迁移至成本更低的存储介质那里,以此来释放 Hadoop 集群所面临的计算压力。
总结

建立模型,这是数据库设计最初阶段要做的事,当进入日常运维时,便涉及到对 SQL 进行优化,之后针对海量数据,需负责其全生命周期的管理工作,在这一系列环节里,元数据始终都存在。
它不仅是数据仓库的“灵魂”,更是技术人员手中的“手术刀”。
深入地去理解,并且善于运用元数据,这能够使得,数据库的每一回查询,都以精准的状态命中目标,每一次的运维,都朝着有的放矢的方向去进行。
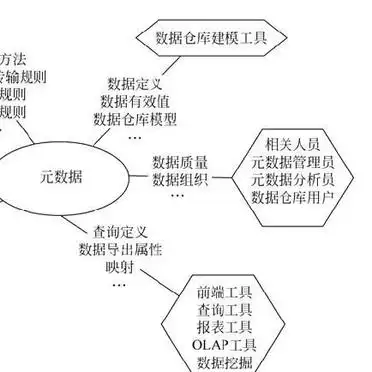
掌握元数据,即掌握了数据仓库优化的主动权。
Comments NOTHING