
云数据库RDS高可用架构下的数据恢复与性能优化实战
身处当下这个电商进行大规模促销以及存在高并发业务的场景里面,数据库的稳定程度以及数据的安全性属于企业赖以生存的关键所在,很重要。
在面临需要开展数据恢复操作的情况之时,或者处于需要着手进行迁移操作的状况之下,具备严谨性的操作流程并且拥有深度水平的技术调优才是保障数据一致性,以及确保系统性能的关键所在。
基于时间点的精确恢复与临时实例构建
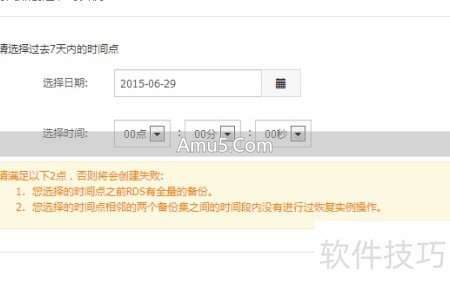
对于逻辑错误或者误操作而言,基于时间点的那家叫做恢复(PITR)的,是最佳的选择。
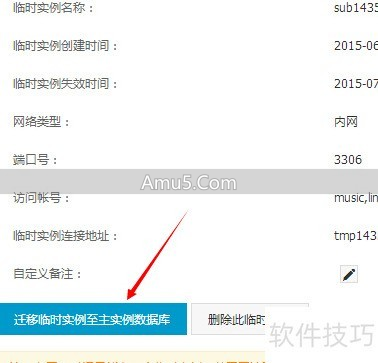
存在于RDS控制台里,首先要挑选出一个精准的恢复时间点,系统会自动地从全量备份以及后续的binlog之内重构出一个临时实例。
这一流程依靠底层分布式存储的“快照”技术,以及“增量日志”的回放,以此保证数据能够恢复到任意一秒的那一种状态。
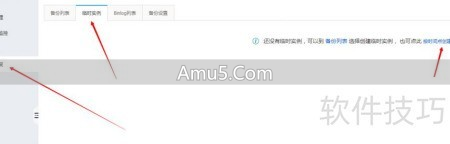
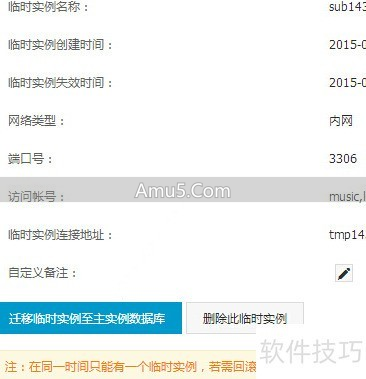
创建临时实例,这不仅是一种用于数据找回的手段,而且还常常被应用于在隔离环境里去验证数据的完整性,以此来防止对生产库产生再次的冲击。
数据迁移前的目标库清洗与表结构校验
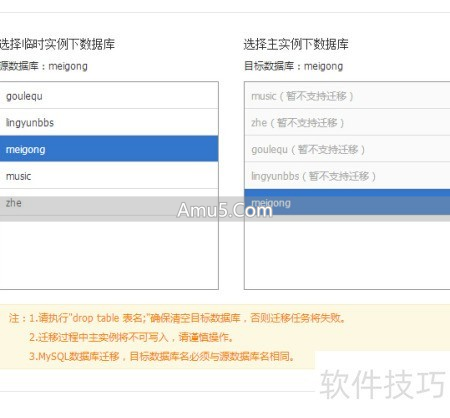
往由临时实例迁回生产库的数据之前,对于目标数据库,那可得进行数据清空这般的操作才行,是必须要做的哟。
此时需谨慎处理表的外键约束与自增主键冲突。
打开数据库连接之后,提议运用 TRUNCATE TABLE 指令消除数据表,该指令的执行速度要比 DELETE 更快,并且还能够对自增计数器进行重置。
但是需要留意,TRUNCATE 不能够被用于存在外键关联的表这种情况,在这个时候,应该优先去处理子表,或者是暂时把外键检查给禁用掉(SET FOREIGN_KEY_CHECKS=0)。
与此同时,一定要去对比源端跟目标端的那个被特别标注为表结构的(DDL),要保证字段类型、字符集以及索引定义全部都一致,这可是迁移成功的基础所在啊。
高效数据迁移与增量同步策略
在DMS里,或者在数据传输服务当中,去配置迁移任务之际,做出正确的选择,针对源库与目标库,这是非常关键重要的。
说到MySQL迁移,DTS工具一般是支持全量迁移的,同时还支持增量数据同步,以此达成业务无感知的平滑切换。
当执行了START TRANSITION,或者点击了迁移按钮之后,系统会去拉取源库的全量快照,并且会一直持续不断地去同步于迁移期间所产生的增量变更。
这个过程,涉及到了一致性快照的创建,以及Change Data Capture(CDC)机制的运用,那么需要去监控迁移延迟,以此来确保最终的数据是一致的。
数据库模型设计与索引优化实践
以电商订单表为例,合理的数据库模型设计是性能的基石。
那个名为订单表的(即为orders),应当去包含了order_id(此乃主键方面)、user_id,还有status,以及create_time等这样的字段。
在高并发查询场景下,避免全表扫描至关重要。
例如,查询用户未完成的订单:
SELECT * FROM orders WHERE user_id = 12345 AND status = 'pending' ORDER BY create_time DESC LIMIT 10;

该查询要构建复合索引idx_user_status_time (user_id, status, create_time),借由索引最左前缀原则之用,让过滤跟排序一并完成,防止出现文件排序(filesort)。
复杂业务场景下的联合查询与子查询优化
涉及多表关联的报表统计,需谨慎使用JOIN与子查询。
例如,查询已下单用户及其最新订单信息:
SELECT u.user_name, t.order_id, t.amount
FROM users u
JOIN (SELECT user_id, order_id, amount FROM orders o1 WHERE o1.create_time = (SELECT MAX(create_time) FROM orders o2 WHERE o2.user_id = o1.user_id)) t ON u.user_id = t.user_id;
此场景中,相关子查询可能引发性能瓶颈。
相较于其他方案,更为优化的做法是,借助窗口函数,像MySQL 8.0及以上版本里的ROW_NUMBER()那样,或者先经由JOIN聚合子查询临时表,且要保证被驱动表的连接字段具备索引。
事务管理与高并发下的数据一致性
在金融级交易中,ACID特性是刚性需求。
使用InnoDB引擎时,合理控制事务粒度至关重要。
避免在事务中执行远程调用或复杂计算,防止锁持有时间过长。
关于死锁这一问题,要借助MVCC(多版本并发控制)这样的机制,以及进行合理的索引设计,以此来实现规避。
例如,在进行库存更新操作的时候,要保证更新语句当中所设置的条件能够精确命中索引,以此来降低锁的涉及范围,必要情况之下,可采用特定语句锁住记录并搭配执行重试机制。
读写分离与分库分表架构演进
随着业务增长,主从复制与读写分离成为标配。
主库承担写操作,从库分担复杂查询与报表生成。
配置半同步复制可最大限度保证数据不丢失。
当单表数据量达到千万级别,分库分表势在必行。
能够依据user_id来开展水平撕开,引进MyCAT或者ShardingSphere这类中间件。
对分片键进行选择,此选择会直接为查询效率带来影响,应当要对跨分片JOIN予以避免,借助全局表或者是数据冗余这种方式来解决问题。
日常运维故障排查与性能调优
突发性性能下降时,首先通过慢查询日志定位问题SQL。
借助EXPLAIN剖析执行计划,留意type(就是从ALL朝着const演进程度)、rows(也就是扫描行数)以及Extra(有无Using filesort/Using temporary情况)。
对于那样一种被称作Redis缓存穿透问题的情况,要借助布隆过滤器去进行拦截;与之不同,对于名为MongoDB的事物,就需要着重留意文档模型设计层面以及索引覆盖方面的事宜,这两句话涉及两个不同类型问题相关的应对举措。
常常开展备份恢复演练,以验证备份集的有效性,这是防御数据灾难的最后一道防线。
需构建起包含全方位各个方面、多层次各个层级的数据库治理体系,才可以实现对电商、大数据等各种繁杂业务场景之下稳定运行状态的支撑。
Comments NOTHING