
针对MySQL分布式数据库架构,进行深度的实践探索,该实践聚焦于高可用性设计,同时对性能优化展开全面解析。
于数字化转型涌起的浪潮里面,数据库这一作为核心基础设施的存在,其架构设计直接就决定了业务系统的承载力,以及业务系统的连续性。
以开源为特性,再者稳定,且生态完善的MySQL,于海量数据场景当中,成了主流选择。
然而,当数据量剧增之时,并且处于高并发压力状况下,单实例MySQL渐渐显露出容量方面的瓶颈情况,以及单点故障所存在的风险。
所以,搭建一组具备高可用性、拥有高性能的MySQL分布式架构,已然成为企业级用场的必定经由途径。进而会成为企业级应用的必经之路。
此文会深入解析其关键设计逻辑,着重于数据库设计,关注SQL优化,重视高可用运维,以及多场景落地实践。
一、分布式架构核心概念与设计原则
分布式数据库的实质是,把数据进行分片,使其存储在多个物理节点上,再经由逻辑实现统一,从而对外提供服务。
它的设计得遵照,有着“一致性、可用性、分区容错性”之称的CAP理论的权衡,并且在实际的业务当中,要优先去保障最终一 致性以及高可用,是这样的形式。
于MySQL生态里,架构设计应围绕“分而治之”来开展,借助按业务模块分库这般的 垂直拆分 以处理耦合度问题,凭借分表这种 水平拆分 来 tackled 单表数据量过大问题,并且引入 读写分离 去缓解主库压力。
二、高可用性架构的深度实现
2.1 基于复制技术的高可用方案
以二进制日志作为手段使得主库操作被同步到从库打造出基石般的,传统主从复制达成了数据冗余。
但其存在复制延迟与主库单点故障问题。
进阶方案运用 半同步复制,保证在至少有一个从库接收到日志之后,才去提交事务,以此在性能跟一致性之间达成平衡。
对于自动故障转移而言,能够结合诸如MHA 或者 Orchestrator 之类的工具 ,去监控主库的状态并且提升新的主库 ,借助VIP漂移达成秒级切换。
2.2 集群级高可用方案
MySQL InnoDB Cluster,借助组复制技术,达成多主写入,实现自动故障检测。
其中的核心,是建立在Paxos协议基础之上的组通信,节点之间有着强一致性,以此来保证数据不会丢失。
为了达成应用层的透明路由,需要与 MySQL Router 相互协作,一旦节点出现变动情况,Router 会自行察觉到并且对流量分发作出调整,进而构建起一个完整无缺的原生高可用解决方案。
面向极端高并发情形,MySQL Cluster(也就是 NDB 引擎)选用内存数据库搭配无共享架构,借由数据自动分片以及节点间同步,达成 99.999%的可用性,适宜于电信、金融等对实时性有着极高要求的业务。
三、深度性能优化策略与实践
3.1 数据库与SQL操作优化
性能优化的起始点是,名为 慢查询日志分析 的事项,并且要结合 EXPLAIN 命令去审视相关执行计划。
进行索引优化时,要遵循最左前缀原则,防止出现索引失效的情况,这是因为隐式类型转换或函数操作会造成索引失效。
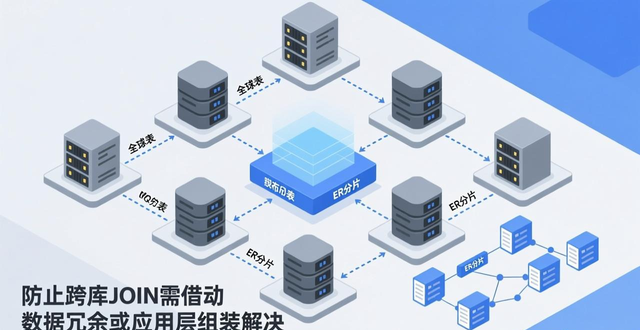
身处分库分表的环境当中,全局表与ER分片的设计显得特别关键着,要防止出现跨库JOIN的情况,需借助数据冗余或者应用层组装来加以解决。
3.2 缓存与存储引擎调优
合规予以运用,把那称作InnoDB Buffer Pool的,将其规模设为物理内存的百分之七十至百分之八十,并且对日志文件大小加以调节,借此降低IO刷新频次。
将有着加强标识的 Redis 引入 ,或者把拥有强调符号的 Memcached带入当作前期置放的缓存用途,具备了热度较高的数据情况时,其命中的概率能够达到百分之九十及以上,在很大程度上减少了数据库穿透所形成的重压压力。
于此同时,运用 分区表 这项技术,依据时间或者范围去拆分大表,进而方便数据进行归档以及能够快速删除。
3.3 硬件与操作系统层优化
挑选 NVMe SSD 这种磁盘,以此来提高IOPS,对文件系统挂载参数加以调整,像noatime这样的,进而减少一些访问时间。
网络层面启用巨帧,调整TCP缓冲区大小,降低主从复制延迟。
于内核参数里头,适度增添文件句柄的数量以及限制,防止在高并发状况下连接出现失败的情况。
四、多场景架构设计案例
案例一:电商交易系统
模式采用“ 业务分开设立数据库+数据进行分割成片”,用户有独立的数据库,订单有单独的数据库,商品存在独立的数据库。
通过按月进行水平分区的订单表格,再借助强有力的 ElasticJob 来实际达成分表数据的路由操作。
在高可用的层面范畴当中,核心交易库所选的是InnoDB Cluster,而非核心库采用的是主从复制这种方式再加以读写分离,并且借助着ShardingSphere-JDBC达成应用层的数据分片以及读写分离这一策略。
案例二:金融支付系统
要求强一致性与审计能力。
采取 两地三中心 的布置方式,核心库依靠组复制来保证数据不存在丢失情况,辅助库借助异步复制开展异地灾备。
通过 gh-ost 工具在线执行所有DDL变更,以便保证使得并实现业务无感知这个状态情况是其结果结果达成模样呈现。
定期去开展全量备份,同时进行Binlog增量备份,另外每月还要开展故障切换演练工作,用以验证RTO与RPO指标。
五、未来展望与运维演进
伴随着云原生技术向前发展,MySQL分布式架构正朝着一种存算分离的状态演进,比如说借助基于K8s的 Operator来达成数据库容器化编排,这极大地提升了资源弹性。
同时,AI技术开始渗透进数据库运维领域,借助智能参数调优以及异常预测,以此来降低DBA人工干预所产生的成本。
往后,多模数据库跟HTAP(混合事务分析处理)能力会更深层次融合,叫MySQL于对高并发事务起到支撑效果之际,还能够承受轻量级实时分析任务。
构架结实的MySQL分布式架构,那可是一项系统的工程,得从业务模型着手,依据数据特征,按照SLA要求,全面使出高可用技术,运用优化策略,借助自动化运维工具。
唯有不断持续推进架构设计的演进,才能够在如洪流般的数据之中确保业务的连续性以及敏捷性,进而切实地释放出数据的核心价值。
Comments NOTHING