
在数据库高可用架构中,数据一致性是金融级业务的核心诉求。
MySQL是作为一种被广泛进行部署的关系型数据库存在的,它的复制协议历经了从异步状态转变到半同步状态的演进过程,然而在面对诸如集群故障切换、脑裂处理等这类复杂的场景时,依旧存在着数据一致性方面的薄弱环节。
从源码逻辑以及集群拓扑的角度出发,针对半同步复制的数据一致性问题进行深度剖析,并且探讨与之相对应的工程优化策略 ,此等作业会在本文中开展。
半同步复制的核心机制与局限
MySQL的半同步复制,目的在于解决问题,什么问题呢,是异步模式之下,主库出现崩溃情况时,所可能引发的数据丢失问题。
它的基本原理是这样的,主库在开展事务提交操作的时候,必须去等待,而且得至少等待个从库接收并且还要写入其relay log,也就是发送ACK了之后,才能够朝着客户端返回成功,是这样的情况才可以提交事务。
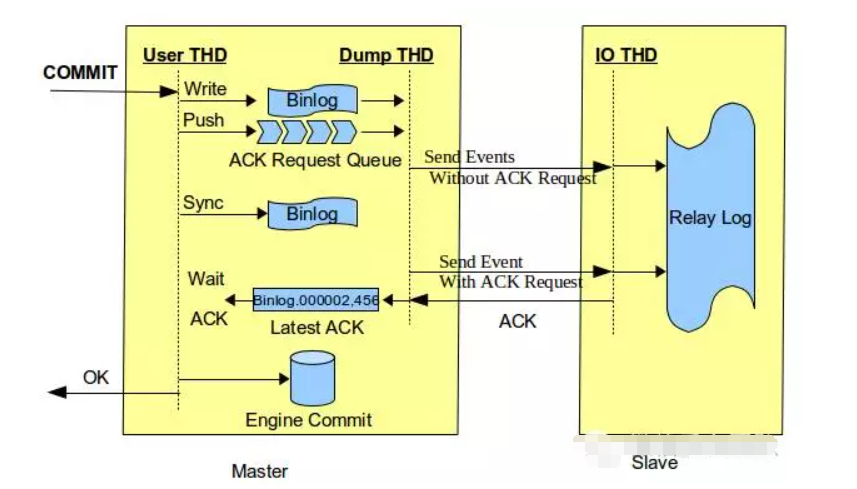
MySQL 5.7所引入的增强半同步,进一步对等待机制做了优化,把等待点,从提交之后,提前到了写入binlog并且刷盘之前,试图达成“zero loss”。
然而,“zero loss”是有严格前提的。
于5.7这个版本里面,主库处在等待ACK的那段期间,事务的binlog未曾完成持久化。
倘若主库于当下猛地崩溃,那么此事务针对客户端来讲是尚未提交的,并且数据没有遗失。
但是,如果主库在接收到ACK之后,并且在事务提交之前出现了崩溃的情况,那么在这个时候,binlog或许有可能尚未被完全应用过来。然而此时,备库却其实已经存有该事务的binlog了,这样一来,就产生了数据方面的差异。
哪怕官方声称已将数据丢失问题予以解决,然而,主数据与备数据不一致的那个时间段依旧是存在着的。
集群故障切换中的一致性黑洞
在实际生产环境中,故障切换远比单点崩溃复杂。
以平常会出现的那种“主库陷于故障停机状态,从库上升到主导地位”的情形作为例子,假定半同步复制被设置成了最少要有一台备用库做出回应。
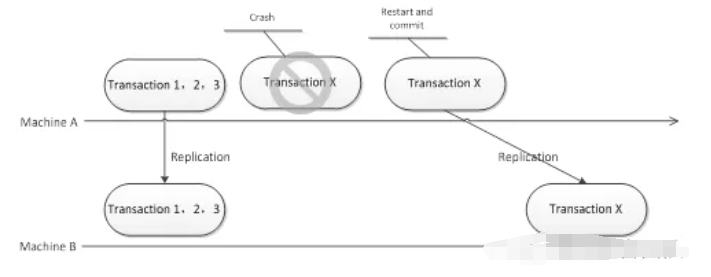
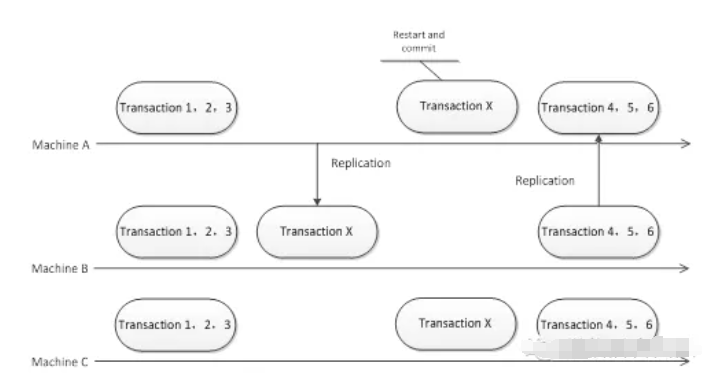
情况一:主库在迎来ACK之后,出现了崩溃的状况。在这个时候,最少存在一台备库,也就是S1,它持有最新的事务。
将S1提升为新主库,理论上数据完整。
然而问题存在于此,当原主库恢复之后再次加入集群之时,它所拥有的事务情况会出现不同,若其在崩溃之前已经完成了提交,那么它的事务数量可能会比新主库多,倘若其在崩溃之前并未完成提交,那么它的事务数量或许会比新主库少。
MySQL原生的复制恢复机制,在某些状况下,会试着让原主库回滚到跟新主库一样的位点,这一行为在生产环境里风险极大,并且可能由于GTID缺失或者binlog丢失致使回滚失败,最终引发主键冲突或者数据不一致。
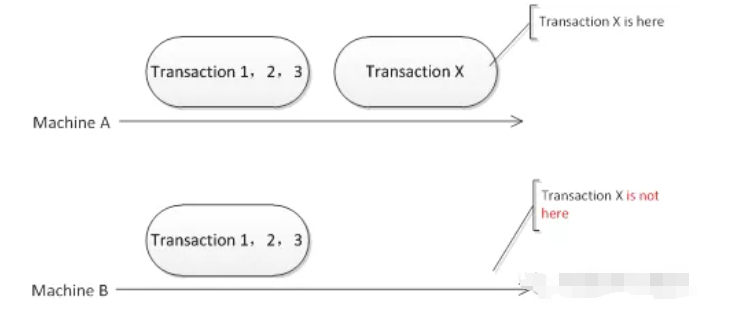
场景B:主库在等待ACK阶段崩溃。 这是最棘手的情况。
事务尚未复制到任何备库,客户端收到超时或失败。
当一台备库被提升为主库后,原主库恢复。
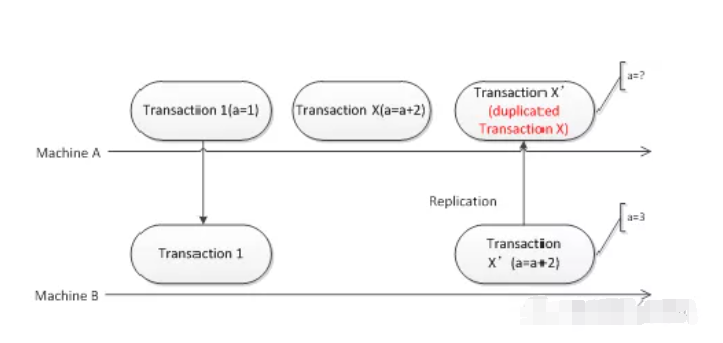
这时,原本的主库之上,或许留存着尚未完结的事务,(处于准备状态,或者已经写入二进制日志但却并未提交)。
假设原主库以新集群的从库的身份启动,那么这其中的残留事务极有被错误执行的可能性,进而致使数据出现冗余或者与业务逻辑不相符合的状况。


比如,有一个扣款事务呢,它在客户端那里已经是失败的状态了,然而,在原本的主库恢复之后呀,它却被应用了,进而导致出现资金错误的情况。
多节点故障与数据共识的缺失
在集群规模得以扩大的情况下,鉴于要去保障读服务具备高可用性,每每普遍会去增多半同步应答的备库数量,像代码示例: `rpl_semi_sync_master_wait_for_slave_count = 2` 这样。
这能够提高数据冗余度,然而却不能够化解分布式系统里的”脑裂“或者”多主写入“问题。
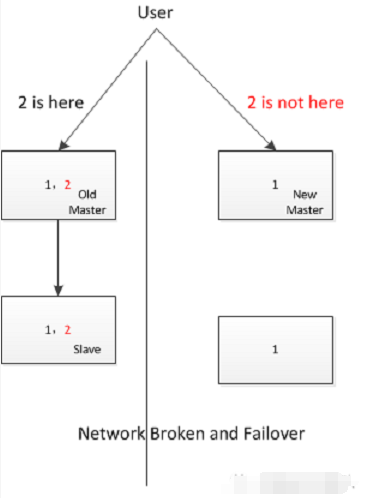
涉及到一个含有五个节点的集群情况下,于主库(A)处于等待两台备库(B、C)进行应答的期间,网络分区出现了。
A被隔离,B在被隔离之列,C也处于被隔离中,然而,要是网络策略给予许可,A依旧会为客户端供给服务。
这时,B以及C,还有剩余的D、E节点,要是引发了新的主库选举,那么D会成为新的主库,并且开始接纳写入。
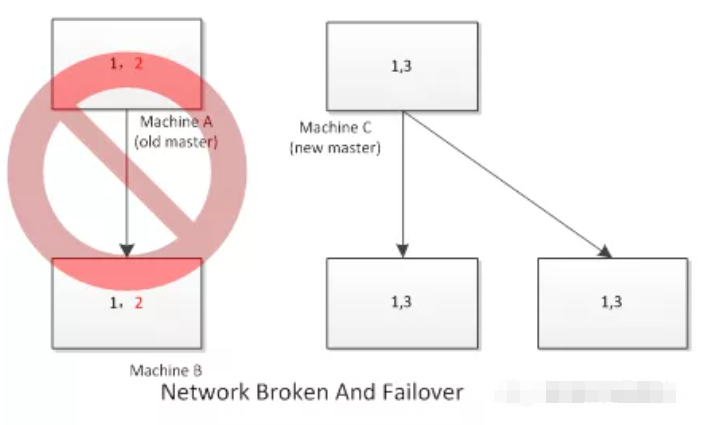
在网络恢复之后,集群当中呈现出两个具备可写状态的主库,这两个主库分别是A以及D,它们两者所拥有的数据没办法进行合并,进而导致集群数据的一致性被彻底地破坏了。
MySQL自身缺少共识算法,(可以这么打比方),比如像Paxos算法或者Raft算法那样的,来裁定究竟是哪个节点持有最新的数据。
在上述所提及的场景状况之下,就算是存在着半同步复制这种情况,那也是没有办法去阻挡由于错误切换而致使的数据分裂现象发生的。
工程化应对策略
需于MySQL集群时,趋向强一致性,必定依靠外部组件,或者架构改造。
于主库路由以及故障切换的管理方面,选用Consul、etcd或者ZooKeeper,以此实施分布式共识协调器的引进操作。
需获得多数派投票(Quorum)的节点,方可成为主库,以此从根本上杜绝脑裂现象。
比如说,将MHA或者Orchestrator的强化版脚本相结合,于切换之前,强行清理,抑或是阻塞,那些有可能产生冲突的旧主库流量。
图8
去强化数据校验和修复,定期运用pt-table-checksum之类工具,对主从数据开展一致性验证,察觉出差异之后,使用pt-table-sync予以修复。
但这属于事后补救,无法保证实时一致。
3. 退化与限流策略:当半同步复制因为备库不足出现超时情况,或者发生降级时,马上熔断主库的写流量,拒绝服务,一直到半同步复制恢复正常状态。
这尽管是以牺牲可用性为代价,然而却确保了数据的绝对一致性,这是金融领域相关场景下的必然要做出的选择。
4. 对于优化恢复流程而言,当原主库再次加入集群这个时候,不应该自动去启用复制操作。
应当首先开展离线状况的检查,去对比 GTID 集合,以此确定这些数据究竟是处于领先的态势,还是呈现出落后的情况,在有必要的时候要进行全量的重新构建,而不是简简单单地进行回滚操作,从而得以避免带入脏数据。
MySQL 所具备的半同步复制,极大程度地削减了数据丢失的风险,然而,当面临复杂的集群故障状况时,它自身的机制并不足以百分之一百保障数据的一致性。
实实在在的解决办法在于将外部一致性组件跟严谨的运维流程相结合,去构建一个综合数据保护体系,这个体系内容是半同步复制,还有共识算法,以及精细化恢复。
Comments NOTHING