
到了时序数据管理范畴之中,跟着业务规模从相对不大到逐渐扩大,以及监控粒度从较为宽泛到慢慢细化,数据量就呈现出如同爆炸一般急剧增长的态势。
这不但针对时序数据库的底层存储架构以及查询性能给出了极为严苛的要求,而且还对数据从产生的一端到进行分析的一端的整个链路的通畅性造成了巨大的挑战。
于传统模式之中,数据的采集跟存储常常是相互割裂的,用户得投入诸多精力去维护开源组件(像Telegraf、Prometheus这类的)的运行环境,与此同时还得去应对存在多采集源状态难以统一管理情况的运维痛点。
对着这样的一种当下状况,现今的时序数据库解决办法已经不会仅仅被限定于单独一个的存储引擎进行优化,而是朝着数据进入的口子去延展,借助搭建自动化、智能化的采集服务体系,切实达成“采、存、查、析”的一体化。
下面将会针对数据库设计,以及SQL操作,还有运维技巧,深入剖析怎样借助技术手段打通时序数据的“最后一公里”。
一、数据库设计:为自动化采集构建高效的存储模型
在实现自动化采集之前,数据库的Schema设计至关重要。
拿阿里云时序数据库来说,它的底层存储模型作出了针对高频写入、批量查询的深度优化。
在创建数据库时,建议根据数据来源和业务属性进行逻辑隔离。
比如说,于采集系统进行监控数据的操作期间,我们构建了一个被称作 monitor_db 的数据库。
不同于传统的那种关系型数据库,时序数据库不需要预先去创建复杂的表结构。
然而,是为了促使查询效率得以提升,故而需要对 Tag(标签)以及 Field(字段)进行合理的设计。
具有高基数且常常被用于过滤的元数据,像是主机IP(host_ip)、数据中心(region),通常会被存储在Tag里,只是Field存储的是具体的指标值,例如CPU使用率(cpu_usage)、内存占用(mem_used)。
关键设计技巧:
针对于不同精度的数据,要设置不同的保留策略(Retention Policy, RP),针对保存周期的数据,也要设置不同的保留策略(Retention Policy, RP)。
举例来讲,留存至7天的,是原本的秒级数据呢,至于已由秒级数据经过转换得来的小时级数据,其保存期限则为30天哦。

在采集配置里头,直接去指定数据写入的那个 RP,能够自动化实现数据生命周期的管理,防止存储的空间出现无限膨胀的状况。
Shard Group设计:理解时序数据库底层的分片机制。
通常情况下,数据会依据时间来实施分区,具备合理性的Shard时长能够对写入性能以及查询效率予以平衡。
在高频采集的场景当中,过长的Shard,会致使单个分片变得过大,进而对Compaction效率产生影响。
二、SQL操作与采集配置:从手动到自动化的范式转变
自动化采集关键之处在于,把复杂的SQL生成,以及数据路由规则,固定在采集工具当中。
在传统的那种模式之下,用户是需要依靠手动去编写SQL,从而把数据从诸如MySQL、Redis等这样的源端给拉取到分析库当中的。
处在自动化体系当中,我们借助“采集配置”这个抽象的概念,去对数据流实施管理。
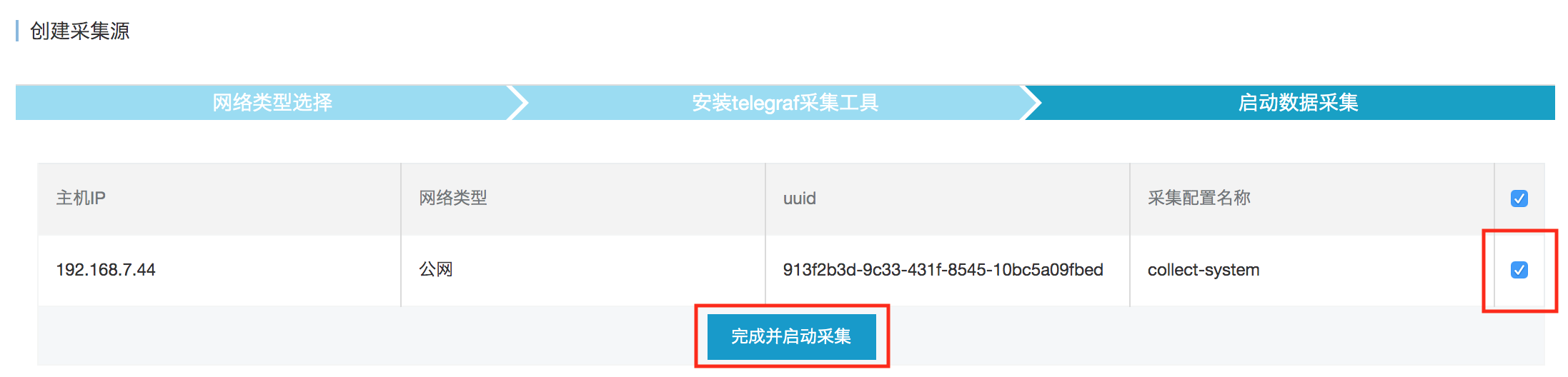
操作案例:采集系统监控数据
1. 创建采集配置(定义数据模型):
于控制台之中,进行采集配置的创建,此采集配置之名,为“server_metrics_config”。
选定“系统监控”这种类型之后,事实上是于后台生成了一张预定义的指标映射表。
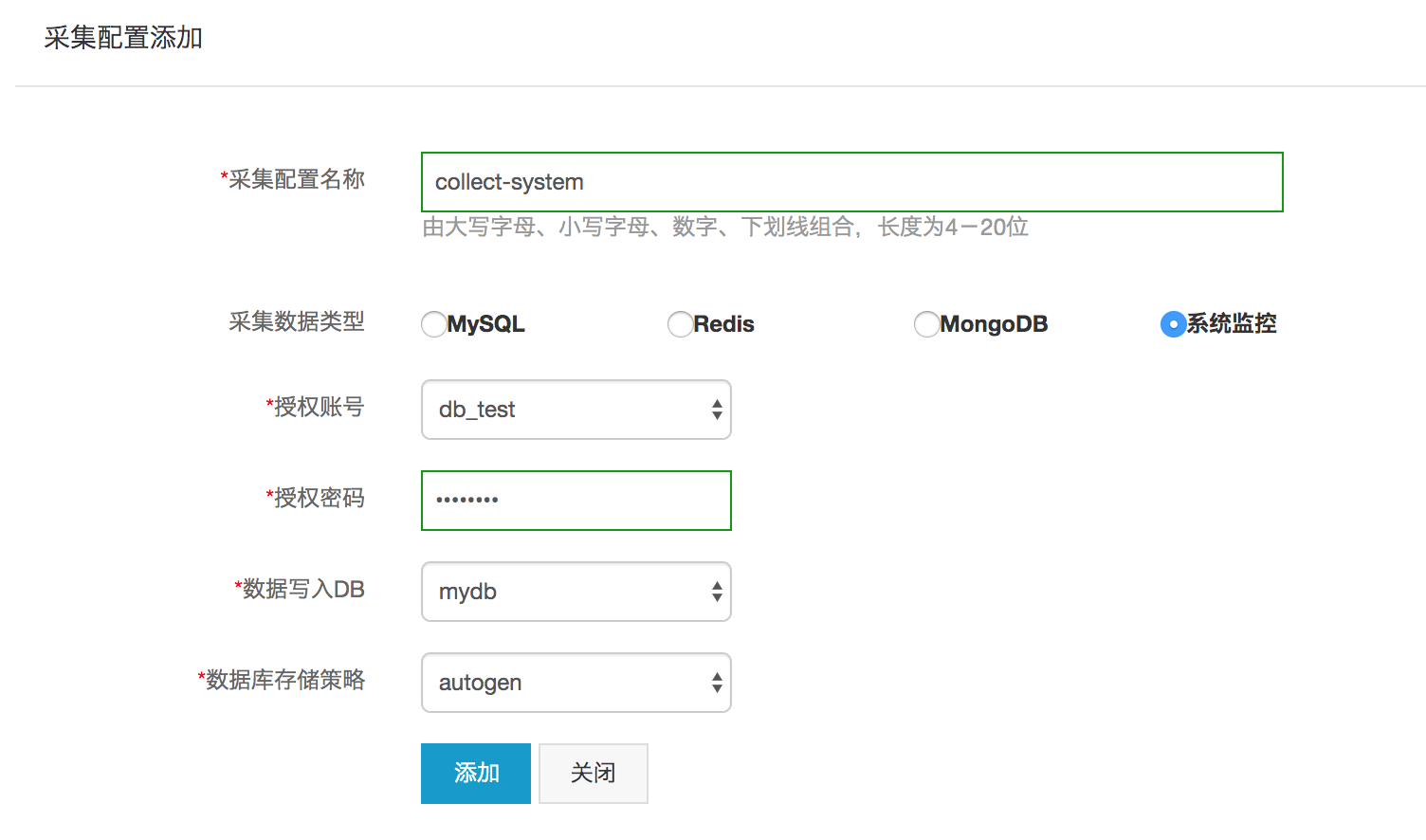
比如说,CPU所产生的数据,会被以自动的方式映射到cpu这个measurement上,其中涵盖着像usage_system、usage_user这类的field。
用户仅需进行选择,选中 “授权账号”,接着指定数据写入之处的目标数据库,像 monitor_db 这般,还要明确保留策略,比如 autogen,如此一来,系统就会自行构建好数据那种的写入路径。
2. 动态SQL注入与转换:

面对复杂采集场景,像围绕MySQL性能监控这类情况,采集工具会自行开展SHOW GLOBAL STATUS指令的执行工作或者针对performance_schema展开查询操作,随后把所返回的结果集转变以时序数据标准的格式呈现。
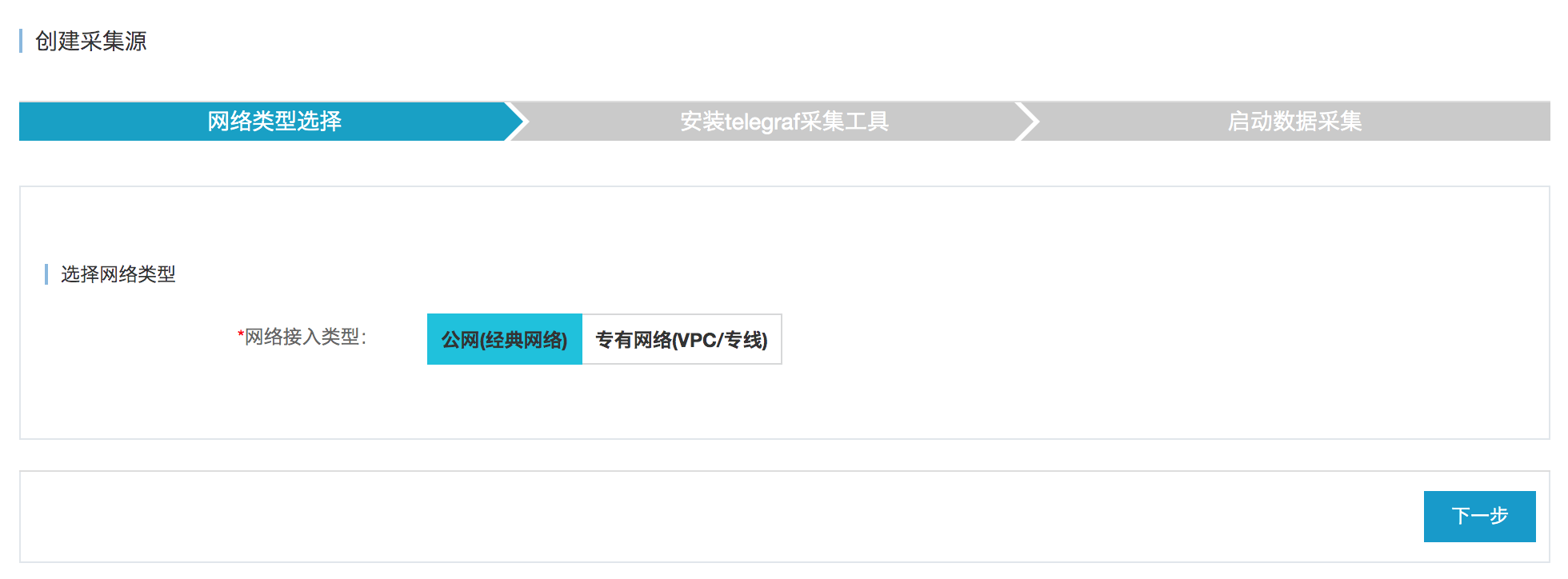
该过程将手动编写ETL脚本所背负的负担予以了消除,达成了从数据源至时序点的毫无缝隙的转换。
三、性能优化与运维技巧:确保采集链路的稳定与高效
数据采集的稳定性直接决定了时序数据的完整性。
以下是几个关键的优化与运维技巧:
1. 批量写入与压缩:
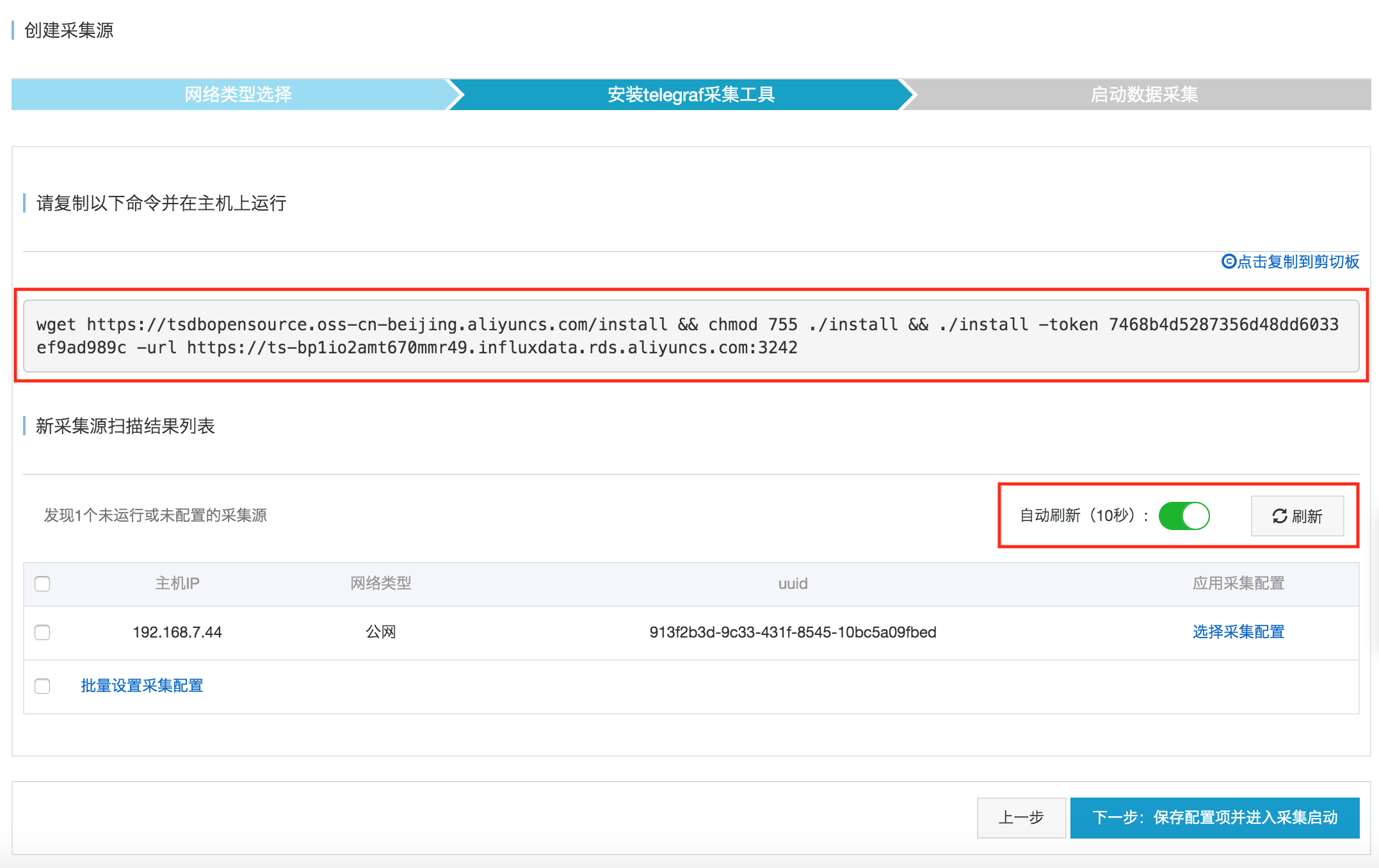
采集工具在主机端并非单点写入,而是采用批量聚合的策略。
以1000个数据点作为一个打包单位,进行批次的组合,之后借助gzip压缩手段,再传送到服务端。
这极大地减少了网络开销,提升了写入吞吐量。
进行运维工作的时候,能够借助查看“最新采集上报成功时间”这种方式,去监控链路的健康程度,要是时间出现停滞的情况,那么就需要对网络或者采集器进程的状态展开排查。
2. 自动化故障转移与缓冲:
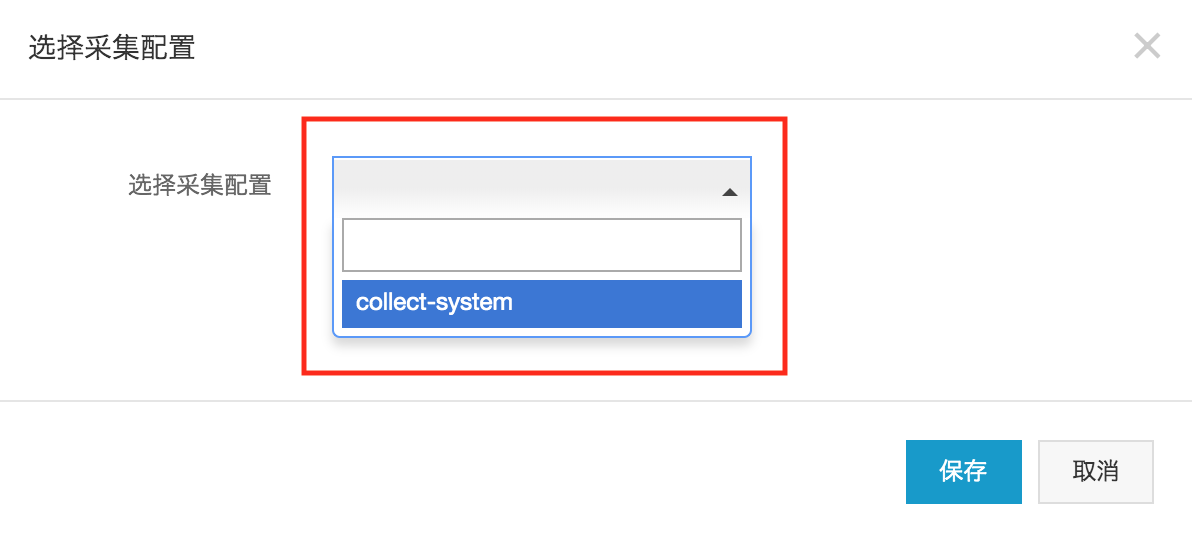
若数据库实例因维护或者故障暂时处于不可用状态 具备生产级才能的采集客户端会于本地磁盘开展数据缓冲 这恰似Kafka的持久化。
等待数据库恢复完成之后,客户端将会主动往回转传递久押未传送的数据这一行为,以此进而保证数据不存在任何丢失的情况。
这一机制要求在主机上预留足够的磁盘空间作为缓冲池。
3. 查询性能的降本增效:
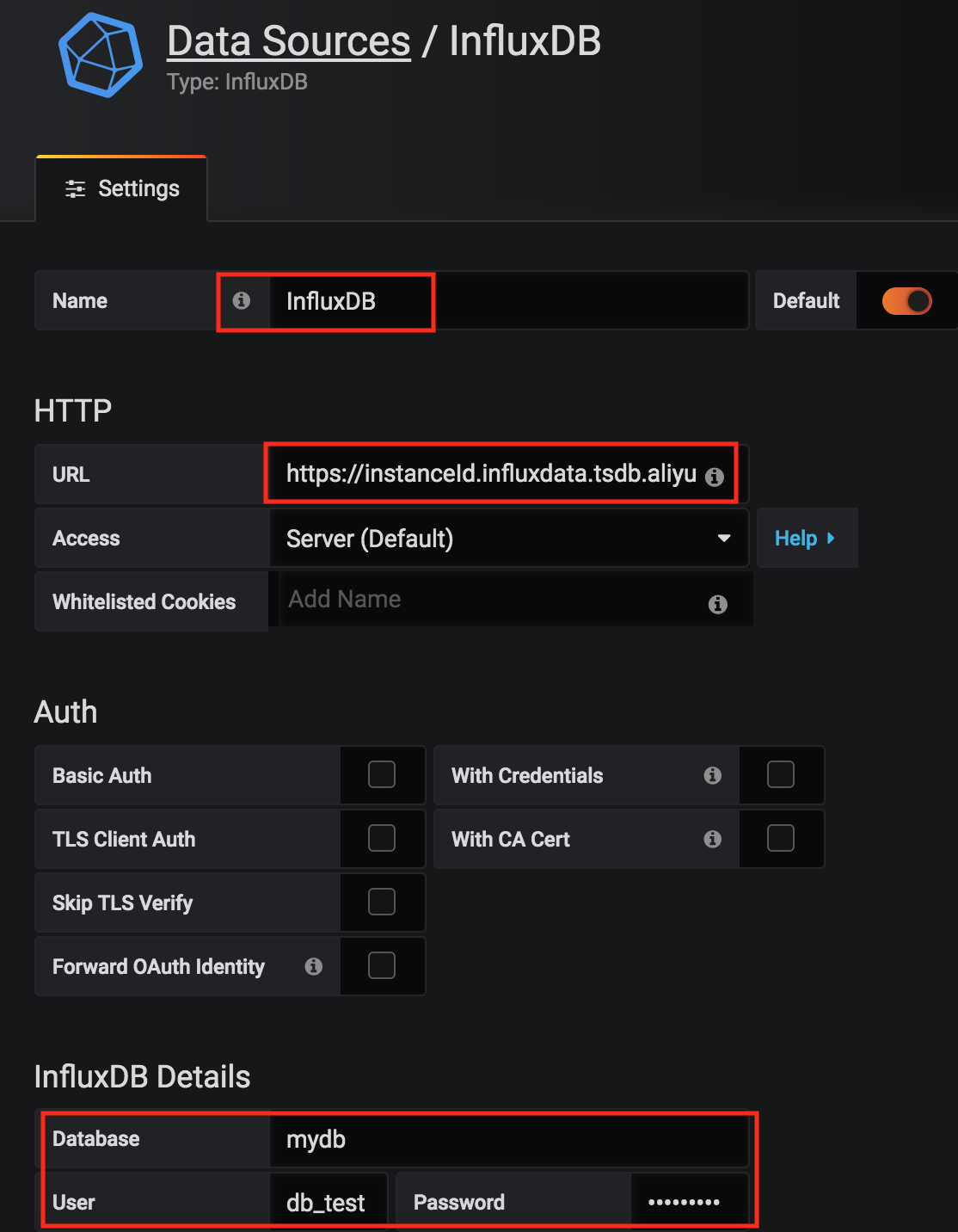
数据接入后,查询优化是释放价值的最后一步。
以在Grafana中查询磁盘使用率为例:
SELECT mean("used_percent") FROM "disk"
WHERE "host" =~ /^$Host$/ AND $timeFilter
GROUP BY time(5m), "host" fill(linear)
利用合理运用,时间分组聚合,也就是GROUP BY time,连同下采样函数,比如mean这种,能够极大程度降低查询所返回的数据数量,进而提高图表渲染的速度。

从事运维工作的人员,应当防止于较大的时间跨度范围之内,去查询那种原始的、完整数量的数据,而是要依靠预先进行计算的处理方式,或者是釆用降低采样频率的策略。
四、多场景应用:从系统监控到业务分析
随着采集能力的拓展,这种自动化模式可轻松复用到多种场景:
数据库监控>,采集MySQL的每秒查询率指标,采集MySQL执行活动的线程数量指标,采集MySQL中时长超过设定值的查询语句指标等等,存储在称为“mysql_perf”的测量记录里,这样做可用来辅助索引调整优化以及协助开展SQL审核工作。
硬件实施巡检动作,借助IPMI协议来展开,采集服务器温度,还有风扇转速等相关数据,凭借时序数据库具备的异常检测功能,最终达成硬件故障提前发出预警的目的。
借助把数据库能力朝着采集端伸展的方式,我们搭建起一个从数据生成直至存储区域的不间断衔接自动化运作体系。
它不但化解了多源异构数据接入时的运维难题,还凭借精细化的数据库设计以及智能的写入策略,为后续的实时分析跟深度洞察营建了稳固的数据基础。
未来,伴随采集数据类型持续丰富起来,像日志、事件、Tracing 这些,在这种情况下,时序数据库充当统一的数据底座,它所具备的价值便会在更大程度上突显出来。
Comments NOTHING