
在人工智能营造的巨型叙事架构里,监督学习所构成的经历常常凭借其精确程度以及高效特性而率先被人进行传颂。
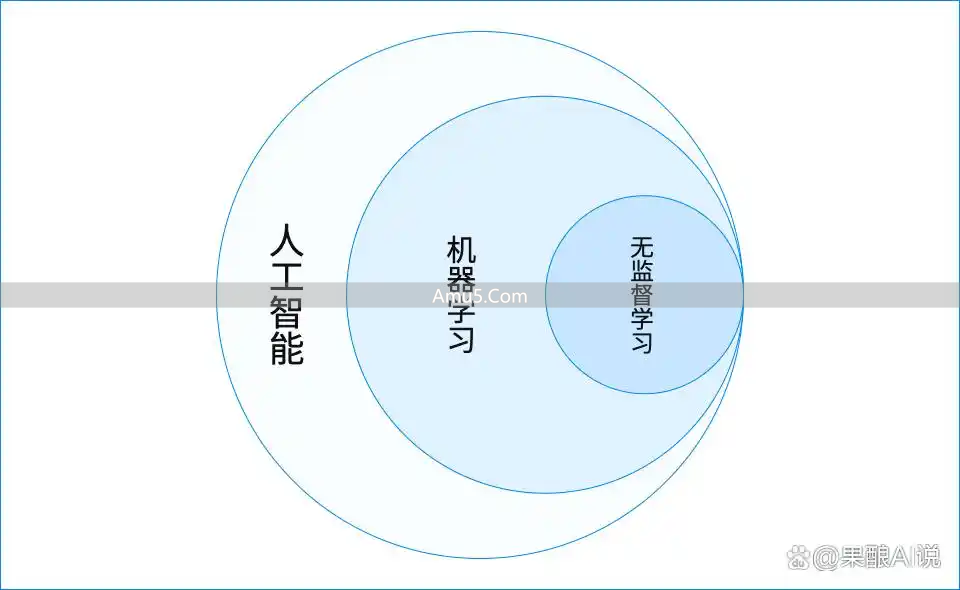
然而,当我们面对那海量且未标记的原始数据的时候,真正的主角,也就是无监督学习,才悄悄地、缓缓地登场了。
它的核心使命不是去模仿那已知的答案,而是要让机器凭借自身能力去探索数据里面藏着的隐秘一种秩序,进而生成有着概率方面意义的洞察。
存在着这样一种能力,它是从数据里“凭空创造”出来的,而这会儿,这种能力正转变成推动产业深度变革的神秘发动机,有着驱动的作用。

以技术底层逻辑作为观察视角,无监督学习的本质显现为,对数据当中内在结构以及模式的自主性发现。
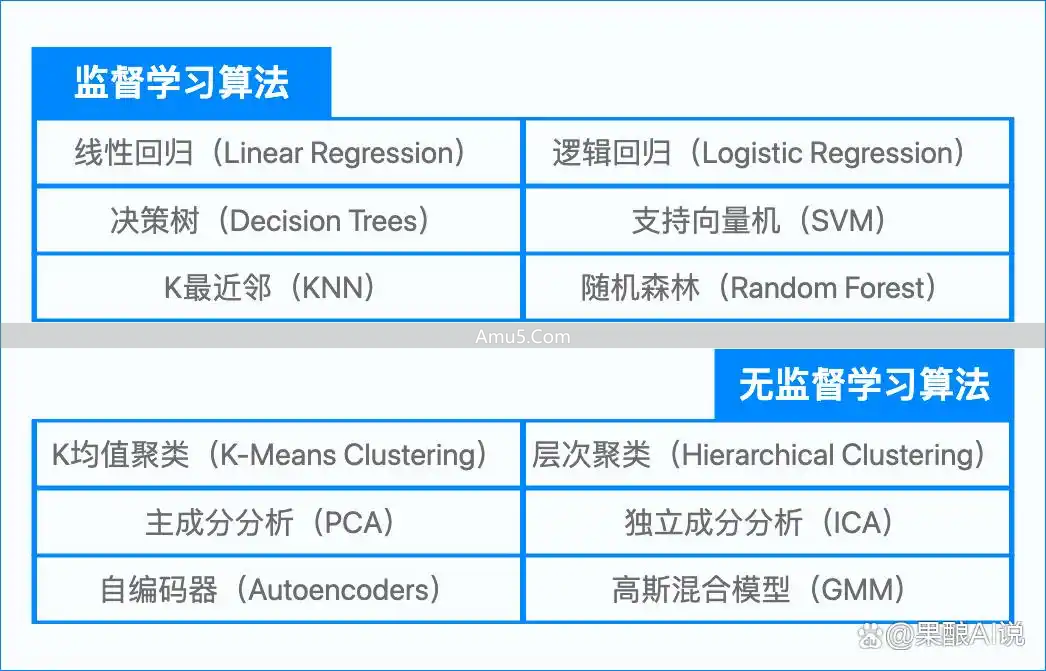
于图像识别范畴里,借由降维来提取关键特征,模型便能够领会像素背后的语义;于生物信息学当中,它能够从海量且众多的基因表达数据内,识别出不一样功能模块;而于文本挖掘以及社交网络剖析里,主题模型和社区发现算法会揭示出隐匿在其中的语义结构以及人际传播路径。
这些技术存在着这样的共同点,那就是,它们全都在不存在“参考答案”的情形之下,去教会机器怎样“看懂”数据自身。
看待当下的市场落实情况,无监督学习的运用已经深入到商业决策的细微之处,已渗透到商业决策的各个角落。

于零售范畴之内,借助剖析客户的购买过往、消费频次等特性,该模型在不具备任何业务先行知识的状况下,能够自行划分出高价值客群、价格敏感型客群等等,从而为精细化运营给予了坚实有力的科学依据。

在推荐系统里,它不再只是留意那般“用户此后会去购置何事”状况(此情形一般是监督学习的工作内容),而是借由探寻用户跟用户、物品与物品两者间的潜在相似特性,搭建更庞大架构的、泛化能力更强的协同过滤网络。
金融风控领域同样是它的主要战场,异常检测算法,能够感触察觉到跟正常交易模式不一样的的数据,进而辨别出新型欺诈手段,这样一种能力,是依靠历史标签的监督学习很难比得上的。
展望往后的三到五年,没有监督的学习会迎来从“辅助于探索”到“成为核心去驱动而作”的角色发生跃迁。
跟着大模型技术的进展,无监督预训练已然成了标配,它凭借海量无标记数据去了解通用表征的本事,将会越发重要。
其一:我们做出预测,自我监督学习这个被视为无监督学习里一个举足轻重分支的事物,会在处理诸如工业传感器数据、金融市场数据这类时序数据方面获取突破,使得机器能够在不存在人工干预的情形下,不停地自我优化行为策略。其二:我们展开预测,自监督而言的学习身为无监督学习相当重要的一个分支,会于处理像工业传感器数据、金融市场数据那般的时序数据之际取得突破,让机器可以在没有人工进行干预的状况下,持续地自我优化行为策略。
另外,于科学探索范畴之内,像新材料找寻、药物分子挑选情形下,无监督学习会作为科学家自高维实验数据里筛选关键变量的标准工具,促使基础研究的范式出现变革,加快变革进程。


然而,光环之下,无监督学习面临的挑战同样不容忽视。

首先是模型的可解释性问题。
当模型察觉到了一种数据模式,我们常常不容易清楚地阐释它那并非一目了然的学习的进程以及并非清晰可辨的决策的依据,这于金融、医疗等有着严格监管的领域形成了构成了合规的风险。
其次是对数据噪声与异常值的敏感性。

极小的微妙扰动存在于数据里,恰似污点在画布之上,这有可能歪曲整个算法对于数据内在结构原本的理解,进而致使模型呈现出 wrong 的聚类,或者识别出虚假的模式。
最后是性能评估的复杂性。
传统的准确率、召回率等指标,因缺乏标签当作“标准答案”,难以适用,怎样客观、量化地去评价一个无监督模型的好坏,依旧是学术界和工业界共同面临的难题。
纵使有着上面所讲的那些局限,无监督学习所开创的机遇之窗正在以从未达到过此等快速程度而打开。
它与监督学习的协同,将构成未来人工智能的完整拼图。
对于海量未标记数据的处理,在探索未知特征之时,于实现自主智能的这些方面,无监督学习有着不可替代的优势。
无监督学习,并非是监督学习的那种可替代之物,而是作为探索未知世界的,另外的一只眼睛。
它把数据当作画布,拿算法当成笔,在不存在任何预先设定轨迹的情形之下,描绘出隐匿于数字洪流背后的真实景象。
对于那些企业来说,它们期望从数据里获取更深层次的洞察,还要构建具有前瞻性的决策能力,深入地去理解以及应用无监督学习,这不再是那种可有可无能选可不选的课程,而是通向未来智能时代必须修习的课程。

在由数据驱动的将来之时刻,哪一个能够更优良地操控这般“自我发觉”的力量,那一个便能够于激烈的产业竞争里获取优先地位。
Comments NOTHING