
现今所存在的监控系统,每一天都需要去处理数以亿计的数据点,怎样能够以高效的方式去存储以及查询这些属于时间序列类型的数据,切实成为运维架构领域的专业人士所面临的最为关键的挑战。
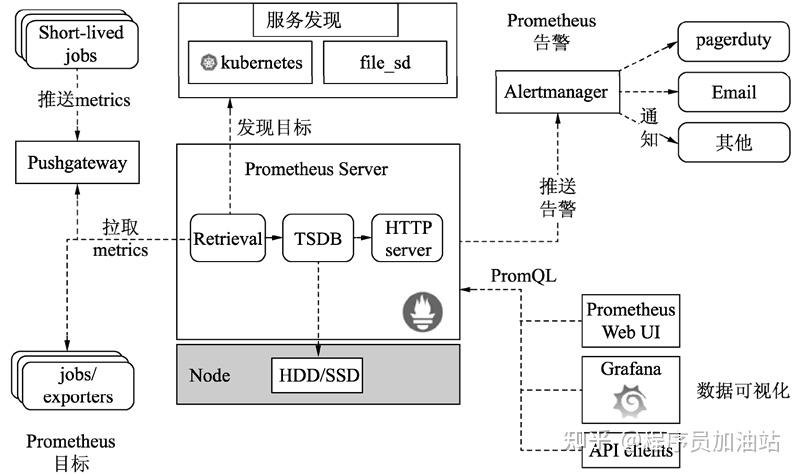
在数万家企业实践当中,开源监控工具Prometheus展现出处理海量监控数据十分卓越的能力,这一能力是借助其独创的时序数据库设计得以证实的。
时间序列数据存储机制
时间序列数据库会把监控指标存储起来,存储时会连同记录时刻的时间戳,以及标签键值对一起存储,最终由此形成十分独特的数据结构。
这样的设计致使每个指标不再处于孤立状态,而是成为了带有丰富维度信息的、具有可追溯特性的数据流。
分块存储策略被TSDB采用,以此将监控数据按时间进行分隔而得成为block,每个block所具备的大小会伴随设定好的步长倍数而呈现递增的情况。
这种机制,是动态分块机制,它有效地平衡了一种矛盾,这种矛盾是数据查询效率与存储开销之间的矛盾。
[{数据压缩与合并优化
在所持续增长的监控数据量的伴随情形之下,TSDB会把小的block按照自动机制合并成大的block,借由减少之下的文件数量达成降低存储占用的目的。
合并过程,减少了内存中需要索引的block个数,大幅提升了查询性能。其提升幅度之大,令人惊叹不已。
每一block借助ULID原理来生成全局唯一的名称,这样的有序ID设计,致使仅凭借文件名便能够确定block的创建时间。
运维人员无需打开文件即可按时间顺序快速定位所需数据块。
WAL预写日志机制
//例如:$ prometheus_build_info{version="2.17.0"}源自关系型数据库的预写日志技术,被用于TSDB之中,以此来保证数据的持久性,以及故障恢复的能力。
当监控数据借助Add接口被增添至head block之际,系统会率先把操作记录书写进磁盘里的WAL文件。
在TSDB出现宕机重启这种情况之后呢,它将触发启动多个协程,以并行的方式去读取WAL文件,借由重演日志把状态恢复到宕机之前的那种状况哟。
存在这样一种机制,它对哪怕系统出现异常中断的情况,都给予了确保,其所保证的是,采集而来的监控数据不会出现丢失的状况。
标签查询与向量匹配
Prometheus把指标名称认作特殊标签__name__,借由标签匹配器组合达成精准查询。
包括等于,不等于,正则匹配等的匹配操作符,能够如同SQL的where条件那样筛选时间序列。
向量匹配,它支持one-to-one这种关系,同时它也支持many-to-one这种关系,它与数据库的左右外连接操作相类似。
//例子:avg(irate(node_cpu_seconds_total{job="node"}[5m] by (instance) * 100))具备如此这般的设计,会导致源于不一样作业的指标能够以一种灵活的方式进行关联,从而去顺遂复杂监控场景所提出的分析方面的需求。
预测函数与统计分析
允许运维人员进行标签拼接操作的是label_join函数,,允许运维人员进行标签提取操作的是label.Join函数,允许运维人员进行标签删除操作的是label_replace函数。
//计算主机上的CPU数量,可以使用count聚合实现
count by (instance)(node_cpu_seconds_total{mode="idle"})
//接下来将此计算与node_load指标结合起来
node_load1 > on (instance) 2 * count by (instance)(node_cpu_seconds_total{mode="idle"})
//这里我们查询的是1分钟的负载超过主机CPU数量的两倍的结果若存在定义的目标标签不存在这种情况,那么系统将会自动把该目标标签添加至标签集合里,这非常显著地增强了相关指标的可定制特性。
该函数以统计为目的针对时间窗口里的样本借由简单线性回归来开展,能够将未来此时此刻那指标数值予以预测,此函数名为predict_linear。
这个函数返回的结果,不会带有度量指标,仅仅保留标签列表,它特别适用于,磁盘空间耗尽预警等这类场景。
//查看主机上的总内存
node_memory_MemTotal_bytes
//主机上的可用内存
node_memory_MemFree_bytes
//缓冲缓存中的内存
node_memory_Buffers_bytes
//页面缓存中的内存node_memory_Cached_bytes
//通过以上的就可以计算出内存使用率
(总内存-可用内存-缓冲缓存中的内存-页面缓冲中的内存)/总内存 * 100主机监控实战应用
Node Exporter所收集的node_load1指标,反映的是1分钟平均负载,借助于与CPU核心数进行对比,能够判断系统饱和度。
1024 * sum by (instance) ((rate(node_vmstat_pgpgin[1m]) + rate(node_vmstat_pgpgout[1m])))当平均负载,长时间超出CPU数量,这种情况就表明,主机资源已然达到处理极限。
依据node_memory前缀的指标,内存监测对使用类型进行细分化,将磁盘读写指标与之相结合,进而能够全面剖析内存饱和度。
磁盘使用百分比会依据文件系统监控,针对每个挂载点进行返回,借助predict_linear函数,能够精确预测出磁盘耗尽的时间。
你是否在日常运维中遇到过因监控数据爆炸导致系统崩溃的情况?
//node_filesystem_size_bytes指标显示了被监控的每个文件系统挂载的大小。node_filesystem_size_bytes期待于评论区域展现你的处置经历,予以点赞并进行转发,从而致使更多做相同工作的人能够目睹这些切实可行的监控手段。
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100
Comments NOTHING