
在Python于TIOBE编程语言排行榜上一直占据榜首位置之际,鲜少有人察觉到这门号称“简易、易于学习” 的语言背后蕴含着将近30发展历程的计算机科学的精粹。你每日敲下的def以及class,实际上都是众多工程师针对内存管理、并发冲突、代码组织等繁杂难题所精心设计的巧妙解决办法。
内存管理的双刃剑
PyCon在2023年时,Meta的工程师分享了Instagram的实践情况,其中表明,合理运用弱引用以及显式del调用,可使内存占用降低30%以上,而Python具备自动垃圾回收机制,这使得开发者告别了C语言里手动释放内存的噩梦,该机制采用引用计数为主、标记清除和分代回收为辅的策略,一旦对象的引用计数降为零,那么内存会立刻被释放。
但自动管理并不等同于完全托付,循环引用致使的内存泄露在Web应用里屡见不鲜,特别是大型Django项目长时间运行之后。深圳有一家跨境电商公司,在2025年初重构订单系统时发觉,未正确关闭的数据库连接以及回调函数中的循环引用,使得每个Worker进程的内存占用从200MB扩大到1.8GB。
函数的魔术参数
最强有力的位置参数打包成元组,这是Python函数签名里最灵活的设计之一,它被称作args,而将关键字参数收拢为字典的称作kwargs,这也是Python函数签名中设计得极为灵活的部分,Flask框架的路由装饰器内部大量运用这种模式,使得@app.route(‘/’)这样雅致的接口得以实现。数据科学家张明于Kaggle竞赛里,借助kwargs来动态传递模型超参数,有一套网格搜索代码,此代码能够适配XGBoost框架,还能适配LightGBM框架,也能适配CatBoost框架。
值得警觉的是,对args的过度使用会致使函数签名变得不易理解。豆瓣的工程师团队在代码规范里清晰规定,唯有在实际参数数量不确定的情形下才可运用,像装饰器或者适配层这类情况。不然的话,宁愿去写几个默认值为None的参数,以此让调用者确切明白能够传递什么参数。
生成器的暂停艺术
设有yield表达式的函数于调用时非即刻执行,而是返回一个生成器对象,仅如此这般的设计使得Python可为同步语法规格达成异步的效果,每单次next()调用均会于yield该处暂停,留存全部栈帧状态,FastAPI框架恰是依此种机制,协同asyncio达成了每秒处置上万请求的性能。
医疗影像公司推想科技,于2024年借助生成器对CT扫描数据的读取模块予以重构,原本要把5GB的DICOM文件统统加载至内存,改用生成器后按需求逐层读取,内存占用从4.2GB降低到不足300MB,技术总监总结时讲:“生成器并非在节省内存,而是在重新界定数据流经程序的方式。”。
模块与命名空间的迷宫
每一个.py文件均为一个模块,import操作的实质乃是将被导入模块的全局命名空间复制到当下作用域。国内某在线教育平台曾因循环导入致使线上服务雪崩,两个模块彼此引用对方类定义,Python解释器抛出ImportError,运维团队于凌晨三点紧急回滚版本。
dropbox工程师在PyCon 2025的演讲里,展示了他们借由linter工具怎样将global关键字坚决禁止掉。此工具提供了global声明具有的修改全局变量的通道,他们的替代办法是,把需要共享的状态在Context类里进行封装,将实例显式传递。在对十万行级别的代码库实施重构之际,依赖关系清晰得如同等高线地图。
深浅拷贝的隐藏成本
列表进行赋值的时候仅仅是去创建新引用,这恰恰是在Python新手当中最为常见的那种认知误区。浅拷贝会去复制容器的第一层,然而内部对象依旧还是引用,深拷贝则会递归复制所有层级。杭州有一家量化私募运用copy.deepcopy()去备份每日交易策略的配置字典,当数据量从几百KB膨胀到几十MB之后,系统延迟从2毫秒急剧飙升到300毫秒。
对于那些会在运行时被修改的字段,他们所采用的解决办法是采用定义专属 __deepcopy__ 方法来进行处理,而对于静态配置部分,则直接采取共享引用方式,并不进行复制。在技术复盘期间,运维总监着重强调指出:“针对于那些无需独立副本的数据,千万不要进行深拷贝操作,因为这实际上是一种以计算成本来换取开发速度的隐蔽性交易行为。”。

数据库索引的选型战争
B-Tree索引与Hash索引,是MySQL里两种典型的数据结构,前者可支持范围查询以及排序,后者仅能进行精确匹配。字节跳动在2025年开源的那个数据中间件,于分库分表场景当中,针对用户ID查询会强制采用Hash索引,单次查询所耗费的时间为0.1毫秒,相较于B-Tree索引要快15倍。然而,当业务方打算增添按月筛选功能之际,才发觉Hash索引根本不支持,于是只能被迫重建索引表。
def print_directory_contents(sPath):
import os
for sChild in os.listdir(sPath):
sChildPath = os.path.join(sPath,sChild)
if os.path.isdir(sChildPath):
print_directory_contents(sChildPath)
else:
print sChildPath在社交应用Soul里头,架构师于存储用户匹配记录之际,同步维护着用于时间范围查询的B - Tree索引,以及用于精确ID查询的Hash索引。他们凭借额外的50%存储空间,换得了所有查询场景皆在10毫秒内予以返回。这表明不存在完美的索引,仅有契合业务的权衡。
阅读至此你会发觉,Python的每一项特性皆是针对特定问题的解决办法。你在日常开发里最为常用哪一特性去处理棘手难题呢?欢迎于评论区分享你的实战事例,点赞并转发给更多有需求的小伙伴。
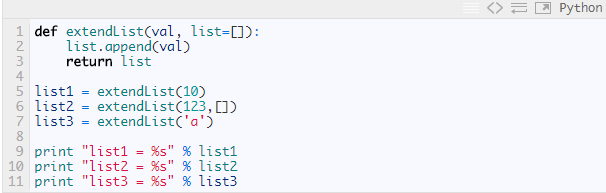
list1 = [10, 'a']list2 = [123]list3 = [10, 'a']
Comments NOTHING