
你知道吗?
归并排序,是计算机科学领域里,极为经典的分治算法当中的一个,它于1954年,被约翰·冯·诺依曼最先提出,直至如今,依旧是各大科技公司在面试时,用以考察候选人算法思维的核心工具。
分治策略的本质体现
归并排序的核心思想其实非常简单而优雅。
它所采用的乃是一种“分而治之”的哲学理念,把复杂程度颇高的大问题,分解成为若干数量的小问题,首先对那些小问题予以解决,后续再把所得结果合并到一起。
在排序的这个场景之内,归并排序会持续地将原始序列均匀地分割成两个子序列,一直到每个子序列仅仅剩下一个元素的时候结束。
这种递归分割的过程在计算机内存中是如何进行的呢?
当程序执行归并排序时,会在系统栈中不断压入新的函数调用。
每层递归调用,都会针对一个规模更小的子数组去进行处理,会持续这一操作,一直到相关子数组的长度变成1的时候,才会停下进行分割的动作,随后便会开启逐层返回的进行。
这个过程完美体现了递归思想在算法设计中的强大威力。
分割过程的详细解析
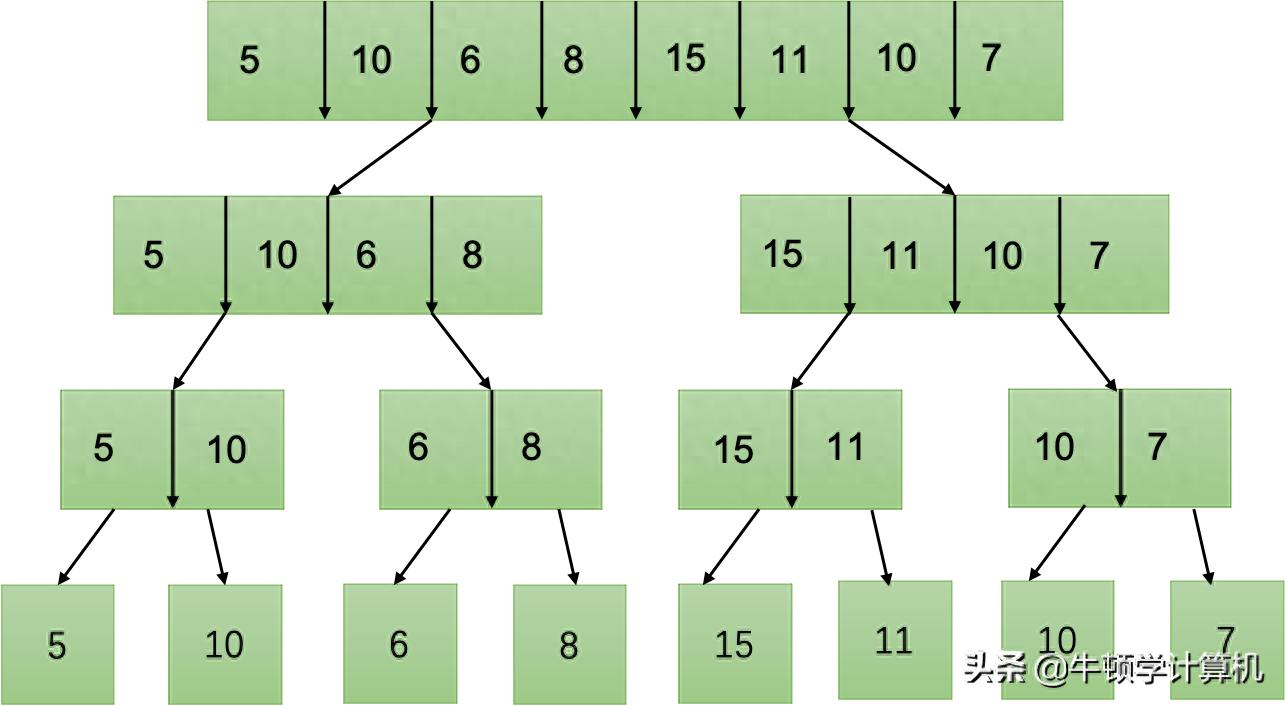
以序列5, 10, 6, 8, 15, 11, 10, 7为例子,归并排序一开始会把这个序列从中间的位置分成两个部分。
前面那一部分是5 ,10 ,6 ,8 ,后面那一部分是15 ,11 ,10 ,7。
这只是第一层的分割,后续当中它的每一半,皆 yet 会持续被划分成更小的子序列,会这样的去生成的。
在分割持续开展的进程当中,前面部分的5, 10, 6, 8将会被划分成5, 10以及6, 8这两个子序列。
然而,后半部分之中的那几个数,也就是15、11、10、7,将会被分割开来,分成15、11以及10、7。
进入到了第三层的那种分割状态,每一个有着两个元素的子序列,又会再次被进行拆分,最终会得出这样的结果,形成了8个仅仅只含有单一元素的子序列,分别是数值为5的单独一段,10独立成段,6自成一段,8单独存在,15独自形成一束,11独立开来,10自成个体,7单独存在,它们各自处于独立的状态!
合并过程的执行机制
合并阶段是归并排序真正产生有序结果的关键步骤。
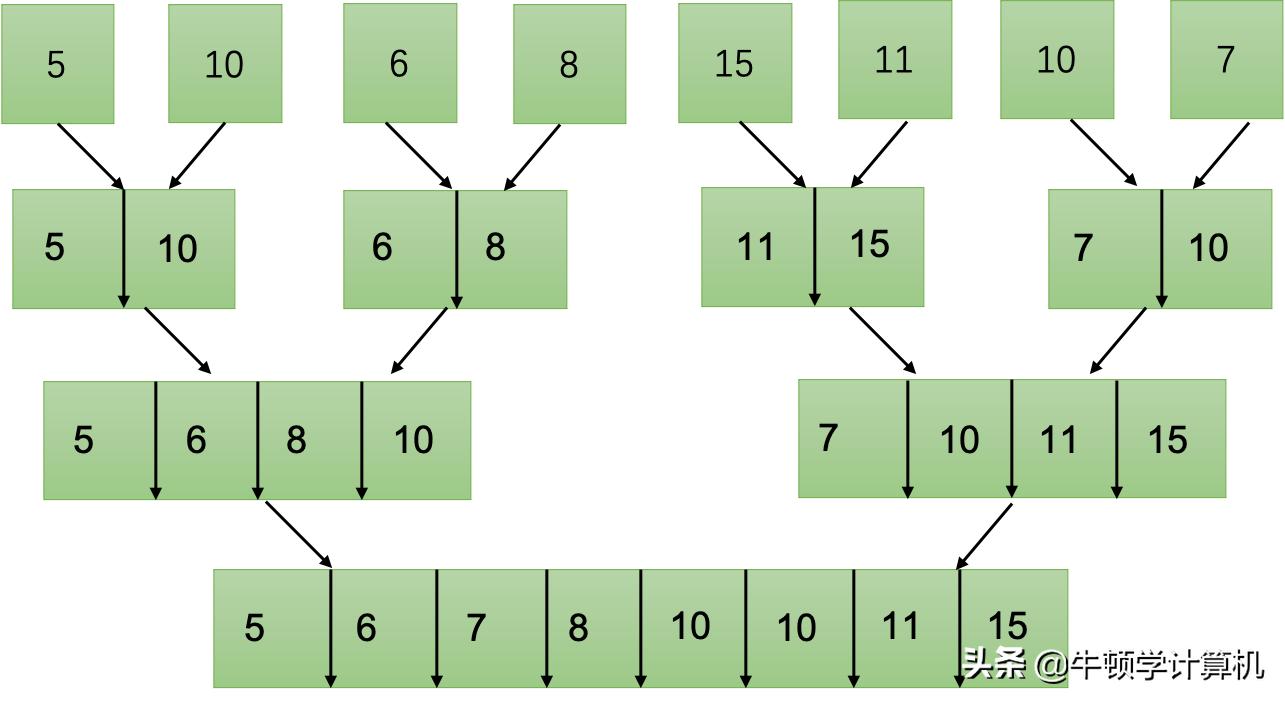
程序起始于最底层的单一元素子序列,会把相邻的俩子序列予以合并。
像5与10这两个子序列进行合并的时刻,算法致使对两个元素的大小予以比较,首先把5放置进临时缓冲区之中,接下来把10放置进去,进而获取到有序序列5,10。
同样的过程会发生在每一对相邻子序列上。
6与8合并成为6,8,当15和11合并的时候会由于11小于15从而得到11,15,而10和7合并就会得到7,10。
在完成第一轮合并这个行为之后,我们获取到了拥有四个两元素子序列的情况。这四个两元素子序列呈现有序状态,分别是:5,10、6,8、11,15、7,10。
static void merge(data_type_t *src, int left, int mid, int right, data_type_t *temp){
if(src == NULL || temp == NULL){
return;
}
int i = left, j = mid + 1;
int index = 0;
while(i <= mid && j <= right){
if(src[i] < src[j]){
temp[index++] = src[i++];
}else{
temp[index++] = src[j++];
}
}
if(i <= mid){
//将剩余左边部分拷贝到临时缓冲区
memcpy(&temp[index], &src[i], (mid - i + 1) * sizeof(data_type_t));
}
if(j <= right){
//将右边剩余部分拷贝到临时缓冲区
memcpy(&temp[index], &src[j], (right - j + 1) * sizeof(data_type_t));
}
//将临时缓冲区的内容拷贝到原始缓冲区中
memcpy(&src[left], temp, (right - left + 1) * sizeof(data_type_t));
for(i = left; i <= right; i++){
printf("%d ", src[i]);
}
printf("n");
}临时缓冲区的关键作用
在合并过程中,临时缓冲区扮演着不可替代的角色。
由两个相邻有序子序列实行合并之际,算法所需具有一块额外的用于内存的空间,以此来进行暂存合并的结果。
这段缓冲区,其大小常常等同于两个子序列长度相加之和,确保可以容纳全部待排序的元素。
会有这样一种算法,它会同时去遍历两个子序列,在遍历的过程中,对当前位置的元素大小进行比较,然后把较小的那个元素放入临时缓冲区。
当一个子序列被完整地遍历完之后,另一个子序列里剩余的全部元素,会被径直拷贝到缓冲区的末尾处。
最终,程序会把缓冲区里所有已经排好顺序的元素,复制回到原序列的对应位置上去。
递归调用的完整实现
void merge_sort(data_type_t *src, int left, int right, data_type_t *temp){
if(src == NULL || temp == NULL || left >= right){
return;
}
int mid = (left + right) / 2;
merge_sort(src, left, mid, temp);
merge_sort(src, mid + 1, right, temp);
merge(src, left, mid, right, temp);
}归并排序的递归实现代码通常分为两个核心函数。
主函数承担着接收待排序数组这件事,还有左右边界索引,当左边界比右边界小的时候,去计算中间位置,接着就递归调用自身以处理左半部分与右半部分,最后调用合并函数把两个有序子序列进行合并。
实现合并函数是需要四个参数的,这参数分别是原数组,还有左边界,以及中间位置,另外还有右边界。
该程序最先测算出左子序列以及右子序列的长度,接着构建临时缓冲区或者径直运用预先分配好的缓冲区。
使用三个循环于合并进程之中:第一个循环展开元素比较以及放入的操作,而后两个循环着手处理剩余的元素。
算法验证与性能分析
凭借编写测试程序去对归并排序予以验证,我们能够直观地察觉到每一步合并之后的序列状态。
使用示例数据来运行程序,控制台将会输出,从底部朝着上方方向,每一层经过合并之后的中间结果。
首次合并之后获取到5,10、6,8、11,15、7,10 ,第二次合并得出5,6,8,10以及7,10,11,15 ,最终合并得到5,6,7,8,双10,11,15。
#include
#include "merge_sort.h"
int main() {
data_type_t arr[8] = {5, 10, 6, 8, 15, 11, 10, 7};
data_type_t temp[8] = {0};
merge_sort(arr, 0, 7, temp);
printf("归并排序结果n");
int i = 0;
for(i = 0; i < 8; i++){
printf("%d ", arr[i]);
}
printf("n");
return 0;
}将元素进行归并排序所用时间的复杂度,在任意状况之下皆是O(n log n) ,就是这样一点,比之于快速排序在最糟糕情形里成O(n²)的表现,显得更具稳定性些。
然而,它存有需要O(n)这一数量级的额外空间用以存储临时数据的情况,而这便是它极为主要的缺点所在。
在实际运用当中,Java的Arrays.sort()方法,针对对象数组的排序,采用了归并排序的理念。
你认为,那种付出内存空间作为代价,来换取稳定又高效的时间性能的归并排序做法,在当下内存日益增大的硬件环境状况下,有没有成为未来排序算法主流选择的可能性呢?
欢迎于评论区对自身的看法予以分享 ,点亮某个赞 ,使得更多的人能够看见这个经典性质的 、有关计算机科学的思想。
5 10
6 8
5 6 8 10
11 15
7 10
7 10 11 15
5 6 7 8 10 10 11 15
归并排序结果
5 6 7 8 10 10 11 15
Comments NOTHING