
归并排序的时间复杂度稳定处于O(n log n),此特性成就其在处置海量数据之际依旧维持高效,进而成为诸多编程语言标准库内排序算法的核心构成部分。
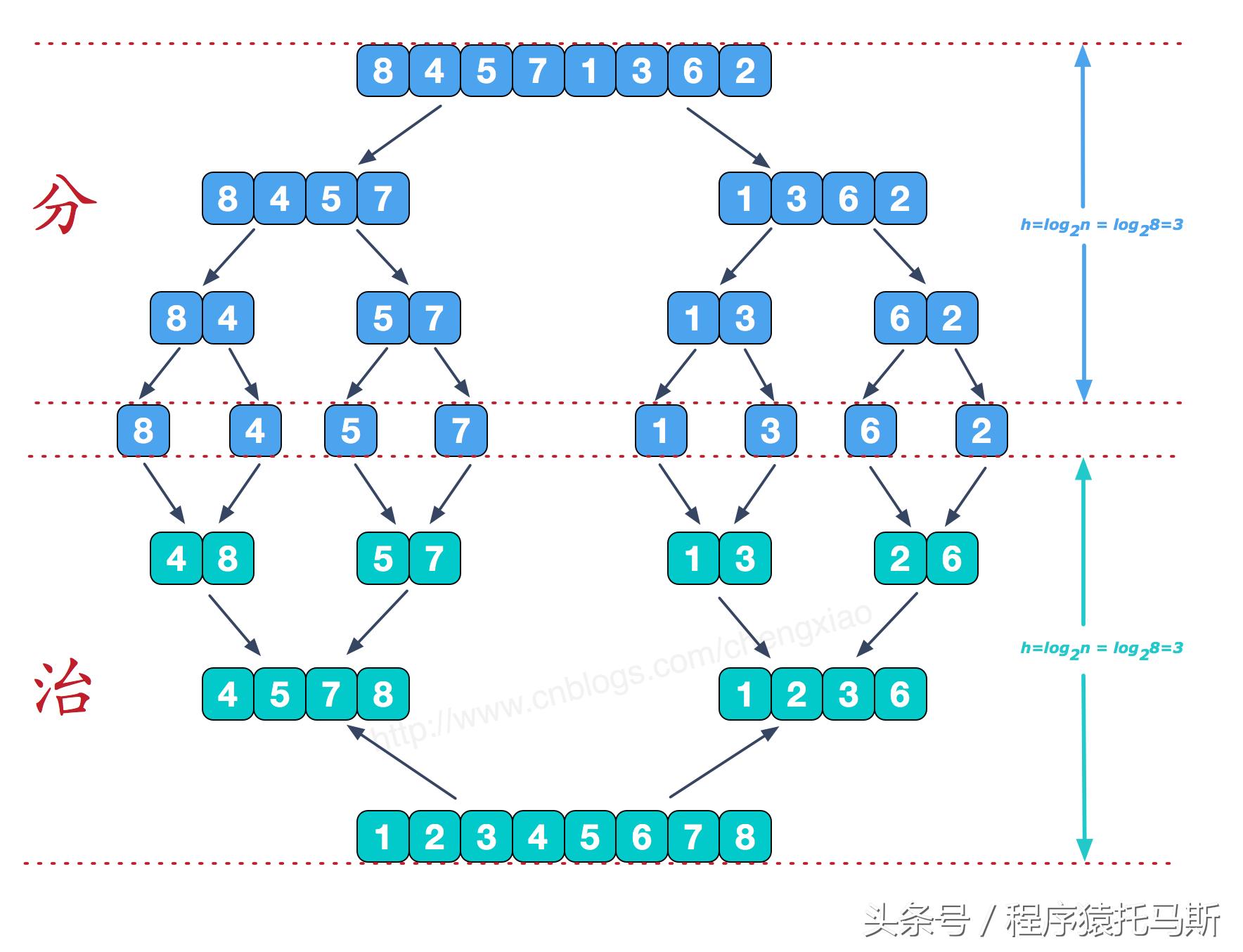
分治策略的递归实现
构成归并排序核心思想基石的是来自分治法哟,要把那种复杂的问题拆解成为若干个简单的子问题进而去处理呢。
最开始的时候,算法会把要整理顺序的数组,从位于中间的那个位置,划分成两种不同的子序列,紧接着,对这两种不一样的子序列,分别开展相同类型的分割行动。
该流程以递归方式开展,一直持续,直至各个子序列仅仅含有一个元素,在这个时候,能够认定每个子序列都是有序的。
分割阶段完成后,算法开始合并相邻的有序子序列。
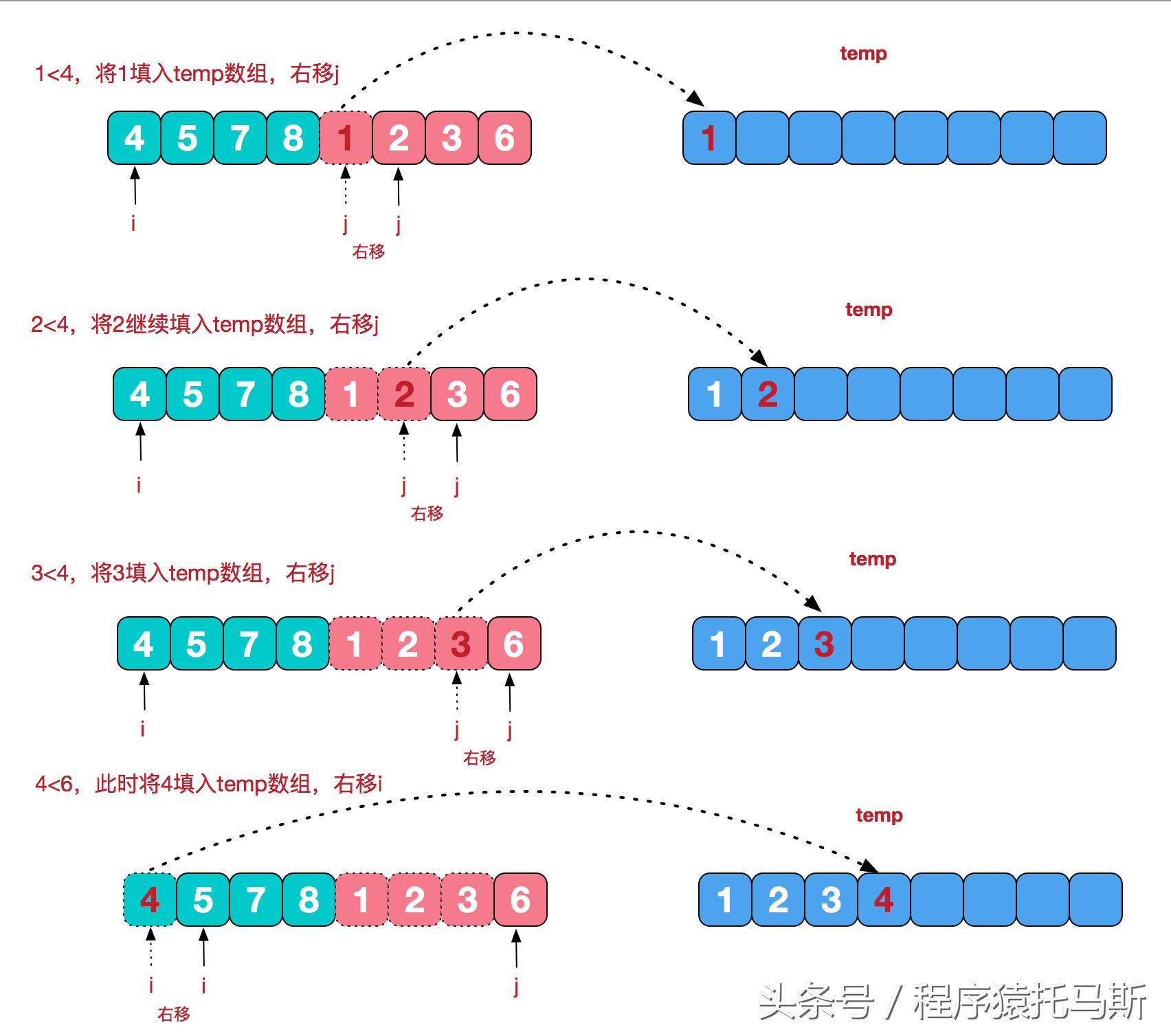
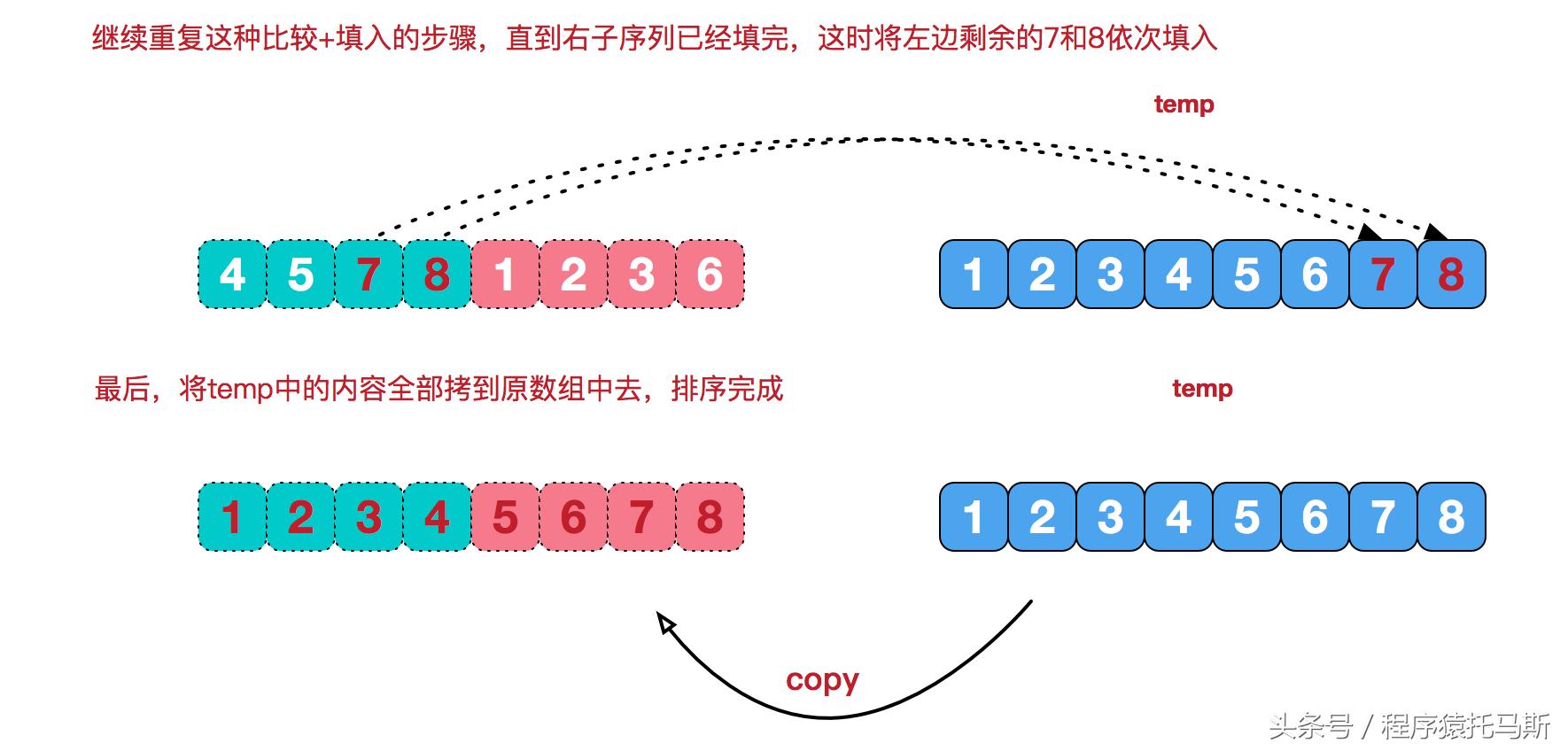
合并操作所需额外空间用于暂存数据,比较俩子序列首元素,小者放进临时数组。
一旦某个子序列的元素尽数被取出,便把另一个子序列的剩余元素径直 Copy 至临时数组的末尾处。
合并过程的精妙设计
归并排序的关键步骤是这个合并且操作,它要同时去处理那两个已经被排序过的数组。
算法会进行维护,有三个指针,其中一个指针指向左子序列的当前位置,另一个指针指向右子序列的当前位置,还有一个指针指向临时数组的当前位置。
不断地去比较两个子序列那些指向元素的指针,把比较可得之为较小的元素放进临时数组,并且呢移动与之相应的那个指针。
这种合并的方式,有这样的作用,它保证了算法具备稳定性,也就是,那些相等的元素在进行排序之后,其相对顺序是不会发生改变的,请注意这一点。
出现相等元素的情况,在左子序列以及右子序列中来临时,算法会优先选取左子序列的元素,此情形对于有保持原始顺序需求存在的场景而言,是十分重要特别关键显著重点突出的。
时间复杂度的数学证明
归并排序的时间复杂度可以通过递归树来精确计算。
设定,有待排序的数组,其长度是n,分割这个操作要求,把数组划分成,两半,然后运用递归的方式,对待排序数组的这两半,进行排序操作。
每一层递归所要处理的元素的合计数量都是n,递归树的深度是log₂n,所以总共需要进行比较的次数大约是n log₂n。
具体而言,关系到实际运行的时间,不论输入的数据是呈正序分布,还是呈逆序分布,亦或是呈随机分布,归并排序都必得进行数量相同的比较操作,以及数量相同的移动操作。
这般稳定性致使归并排序于数据分布不明确的情景里极具优势,然而与此同时这也表明它没办法如同快速排序那般在某些情形下取得更优的性能。
空间消耗的权衡分析
归并排序在执行合并操作时,需要用到和原始数组长度一样的辅助空间,这使得它的空间复杂度变成了O(n)。
两数合并之时,临时数组被用于放置排序结果,最终,排序后的结果会被复制回到原本的数组之中。
这种空间开销对于内存有限的系统可能成为瓶颈。
为减少空间消耗,实际应用中常采用一些优化策略。
比如能够事先分配一个和输入数组同等大小的临时数组,在整个排序进程当中反复加以使用,从而防止频繁地进行内存的分配以及释放。
还存在着一种,是原地归并排序的变体,然而其实现复杂度比较高,且一般情况下会致使性能有所下降。
实际应用场景与变体
归并排序在外部排序中发挥着不可替代的作用。
具备待排序数据量超出内存容量的情况时条件之下,能够把数据划分成多个能够在内存里进行处理的小块,各个小块分别进行排序之后再写入磁盘之中。
然后,采用多路归并的办法,一步步合并这些有序的块,最终,拿到完整的有序的文件。
于那数据库管理系统里头,以及编程语言标准库里,归并排序的运用是相当广泛的。
Timsort算法,属于Python的那种,它是归并排序与插入排序相混合而成的,它具备识别数据里有序片段的能力,还可以将其进行高效合并。
在对对象进行排序之际,Java中的操作是Collections.sort方法,它采用了与优化归并排序相类似的方式,是这样的情况了。
迭代实现方式探析
除了递归实现,归并排序还可以用迭代方式完成。
最先把数组看作是n个长度为1的有序序列,接着从最小的子序列开始去做合并,之后两两合并从而得到长度为2的有序序列,随后不断重复这个过程,一直持续到整个数组变得有序。
#include
#include
#include
#include
using namespace std;
/**将a开头的长为length的数组和b开头长为right的数组合并n为数组长度,用于最后一组*/
void Merge(int* data,int a,int b,int length,int n){
int right;
if(b+length-1 >= n-1) right = n-b;
else right = length;
int* temp = new int[length+right];
int i=0, j=0;
while(i<=length-1 && j<=right-1){
if(data[a+i] <= data[b+j]){
temp[i+j] = data[a+i];i++;
}
else{
temp[i+j] = data[b+j];
j++;
}
}
if(j == right){//a中还有元素,且全都比b中的大,a[i]还未使用
memcpy(temp + i + j, data + a + i, (length - i) * sizeof(int));
}
else if(i == length){
memcpy(temp + i + j, data + b + j, (right - j)*sizeof(int));
}
memcpy(data+a, temp, (right + length) * sizeof(int));
delete [] temp;
}
void MergeSort(int* data, int n){
int step = 1;
while(step < n){
for(int i=0; i>n;
int* data = new int[n];
if(!data) exit(1);
int k = n;
while(k--){
cin>>data[n-k-1];
}
clock_t s = clock();
MergeSort(data, n);
clock_t e = clock();
k=n;
while(k--){
cout<<data[n-k-1]<<' ';
}
cout<<endl;
cout<<"the algorithm used"<<e-s<<"miliseconds."<<endl;
delete data;
return 0;
}
递归算法:
#include
using namespace std;
void merge(int *data, int start, int mid, int end, int *result)
{
int i, j, k;
i = start;
j = mid + 1; //避免重复比较data[mid]
k = 0;
while (i <= mid && j <= end) //数组data[start,mid]与数组(mid,end]均没有全部归入数组result中去
{
if (data[i] <= data[j]) //如果data[i]小于等于data[j]
result[k++] = data[i++]; //则将data[i]的值赋给result[k],之后i,k各加一,表示后移一位
else
result[k++] = data[j++]; //否则,将data[j]的值赋给result[k],j,k各加一
}
while (i <= mid) //表示数组data(mid,end]已经全部归入result数组中去了,而数组data[start,mid]还有剩余
result[k++] = data[i++]; //将数组data[start,mid]剩下的值,逐一归入数组result
while (j <= end) //表示数组data[start,mid]已经全部归入到result数组中去了,而数组(mid,high]还有剩余
result[k++] = data[j++]; //将数组a[mid,high]剩下的值,逐一归入数组result
for (i = 0; i < k; i++) //将归并后的数组的值逐一赋给数组data[start,end]
data[start + i] = result[i]; //注意,应从data[start+i]开始赋值
}
void merge_sort(int *data, int start, int end, int *result)
{
if (start < end)
{
int mid = start + (end-start) / 2;//避免溢出int
merge_sort(data, start, mid, result); //对左边进行排序
merge_sort(data, mid + 1, end, result); //对右边进行排序
merge(data, start, mid, end, result); //把排序好的数据合并
}
}
void amalgamation(int *data1, int *data2, int *result)
{
for (int i = 0; i < 10; i++)
result[i] = data1[i];
for (int i = 0; i < 10; i++)
result[i + 10] = data2[i];
}
int main()
{
int data1[10] = { 1,7,6,4,9,14,19,100,55,10 };
int data2[10] = { 2,6,8,99,45,63,102,556,10,41 };
int *result = new int[20];
int *result1 = new int[20];
amalgamation(data1, data2, result);
for (int i = 0; i < 20; ++i)
cout << result[i] << " ";
cout << endl;
merge_sort(result, 0, 19, result1);
for (int i = 0; i < 20; ++i)
cout << result[i] << " ";
delete[]result;
delete[]result1;
return 0;
}
迭代实现避免了递归调用的函数栈开销,在某些情况下性能更好。
它采用自底向上的策略,通过控制合并步长来组织排序过程。
此种方法格外适宜针对链表这类不支持随机访问的数据形式开展排序,缘由在于能够径直借助指针操控达成合并。
程序编写期间,你会把哪一种排序算法当作优先考量对象,是否曾因对算法原理欠缺了解而遭遇性能的瓶颈状况呢?
欢迎在评论区分享你的经验。
Comments NOTHING