
存在一个简单的称重问题,在99个工件里头找出一个较轻的劣品,要是采用逐个去比较的方法,最多需要50次,然而运用分治思想,仅仅只要4次就能够锁定目标,这样一种效率的飞跃,恰恰便是算法设计之中分治策略所具备的核心价值的根本所在。
分治算法的基本原理

在分治算法里,它是基于三个关键步骤而构建起来的,第一步,要把原始问题给分解成若干个规模较小的子问题,并且这些子问题在形式方面与原问题维持一致,第二步,需分别去解决这些子问题,第三步,最后把这些子问题的解进行合并从而得到原问题的解。
因为小规模问题的解决难度,远远低于大规模问题,所以这种处理方式能够显著降低问题的复杂度。
就拿工件称重这件事情来说,把99个的工件平均分成三组,每组是33个,仅仅通过两次称重,就能够确定劣品所在的那个小组。
小组确定之后,不管此组存在33个工件,还是存在34个工件,持续运用三等分策略,最多再去进行两次称重,便能够找到劣品。
整个过程中总共只需要4次称重操作。
分治策略的适用条件
不是所有的问题,都适宜借助分治策略来处理,运用这种办法,得要符合特定的条件才行。
必须要做到子问题彼此是相互分立的样子,也便是讲,一个子问题被处理好的这种情况,不会对其他子问题的状态产生影响。
在工件称重的相关案例当中,每一组工件具有的质量呀,和其他组是全然没有关联的,如此这般就确保了分治策略具备的有效性。
子问题的规模应该能够持续缩小直至达到可以直接解决的规模。
在数组进行排序期间,当数组的长度被缩减至1的时候,这个数组自然而然地就是处于有序状态的,并不需要开展任何的比较方面的操作。
这种性质使得分治算法能够通过递归方式不断简化问题。
归并排序的分治实现
归并排序属于分治思想于排序范围之中经典适用情形,它能够持续地把待进行排序的数组做二分处理,一直到每个子数组只有单个元素为止。
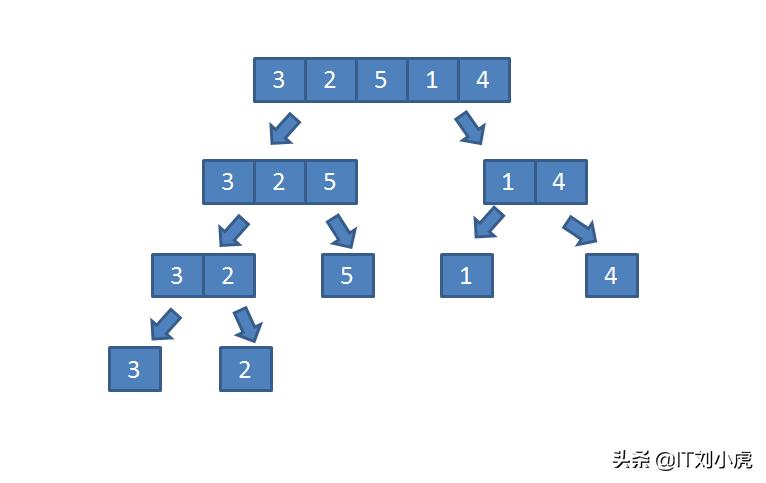
这些由单个元素构成的数组,能够被视作已然排列好顺序的数组,以此为后续的合并操作奠定基础。
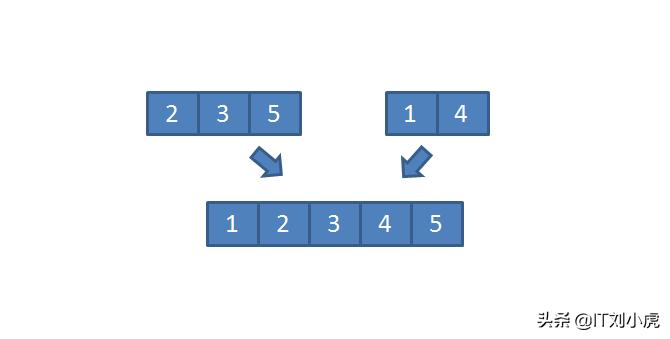
在合并这个流程当中,算法会针对两个具备有序性质的数组的首个元素展开比较,随后会把较小的那个元素依照次序逐个放置到结果数组里面。
在C语言实现中,拆分操作通常采用递归方式完成。
函数接收,数组的首索引,数组的尾索引,计算之后的中间位置,紧接着针对左面一半,针对右边一半,分别去递归调用,它自身,一直持续到,首索引跟尾索引相等。
这种达成方式代码简约并且逻辑明晰,全然借助函数调用栈去管理拆解进程。
合并过程的关键技术
合并操作需要创建临时数组来存储待合并的两个有序子数组。
在C99标准给予支持的状况下,能够运用变长数组这个特性去动态地分配所需要的空间,如此一来,它相对于固定大小的数组而言,是更为灵活的。
void divide(int *arr, int start, int end)
{
if (start >= end)
return;
}算法借助三个循环完成合并,第一个循环比较两个子数组相应位置的元素,然后按照顺序将其填入原数组,后面两个循环分别对剩余的元素进行处理。
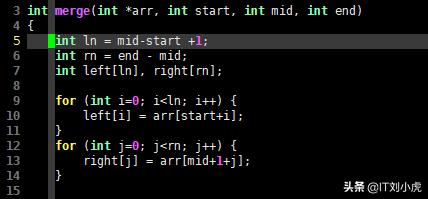
在进行合并这个过程的时候,是特别要求去留意索引边界管理的,左子数组它所处的范围,是原数组从start一直到mid这个的位置,而右子数组所处于的范围呢,是mid加上1以后一直达到end的位置。
void divide(int *arr, int start, int end)
{
if (start >= end)
return;
int mid = (start+end)/2;
divide(arr, start, mid);
divide(arr, mid+1, end);
}在那其中的一个子数组里头,其所有的元素均被处理完成之后,另外的那个子数组所剩余下来的元素,能够直接去进行复制,并放置于结果数组的末尾处。
归并排序的性能分析
int merge(int *arr, int start, int mid, int end)
{
int ln = mid-start +1;
int rn = end - mid;
int left[ln], right[rn];
for (int i=0; i<ln; i++) {
left[i] = arr[start+i];
}
for (int j=0; j<rn; j++) {
right[j] = arr[mid+1+j];
}
}归并排序的时间复杂度维持于O(nlogn)级别,这是由于每次递归会把问题规模削减一半,并且每一层的合并操作得去遍历全部n个元素。
在空间复杂度这一方面来说,鉴于要去开展创建临时数组举动用以存储子数组,所以额外内存开销呈现出为O(n)这种情形。
这种稳定的性能表现使其成为处理大规模数据的理想选择。
于实际的测试当中,针对100万个随机的整数去开展排序工作,归并排序仅仅只需要230毫秒就能够完成。
相对而言,冒泡排序于处理同等规模的数据之际,执行的时间超出了两分钟,然而还没有完成。
int merge(int *arr, int start, int mid, int end)
{
...
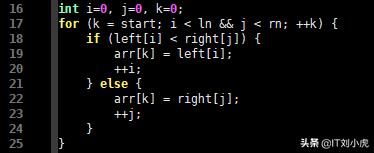
int i=0, j=0, k=0;
for (k = start; i < ln && j < rn; ++k) {
if (left[i] < right[j]) {
arr[k] = left[i];
++i;
} else {
arr[k] = right[j];
++j;
}
}这种差距极大的性能不同,会由于数据规模变大,进而愈发显著,这充分彰显了分治策略于大数据处理当中的优势所在。
分治算法的现实应用
在计算科学领域,分治的这种思想不光运用得较为广泛,于日常的生活当中,它亦是发挥着关键作用的,在工业生产里面,它同样有着重要用途。
抽样检测,于质量管理之中,搜索引擎的分布式处理所在之处,这大规模数据的并行计算,均需有分治策略的支撑方可成立。
这个“化整为零,逐个击破”的想法给处理繁杂问题给出了有效办法。
int merge(int *arr, int start, int mid, int end)
{
...
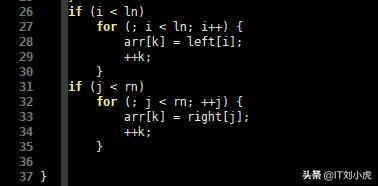
if (i < ln)
for (; i < ln; i++) {
arr[k] = left[i];
++k;
}
if (j < rn)
for (; j < rn; ++j) {
arr[k] = right[j];
++k;
}
}在软件工程实践中,分治思想也指导着系统设计。
个头较大的软件系统,被划分成了好些独立的模块,这些模块各自进行开发,最终借助接口来完成整合。
这种模块化式的设计方案,不但提升了开发的效率,而且还强化了系统的可维护性能以及可扩展性能。
你是否在实际工作或生活中运用过分治策略解决过复杂问题?
如若你认为这篇文章于你有益乎,那就别忘记去点赞以及做一转发之举,从而能使繁多伙伴知悉这个超强大的问题解决工具,同时,欢迎你在评论区域去分享自身之经历。
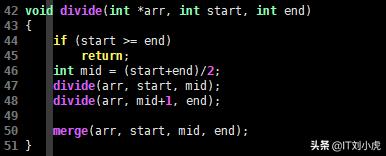
void divide(int *arr, int start, int end)
{
if (start >= end)
return;
int mid = (start+end)/2;
divide(arr, start, mid);
divide(arr, mid+1, end);
merge(arr, start, mid, end);
}
Comments NOTHING