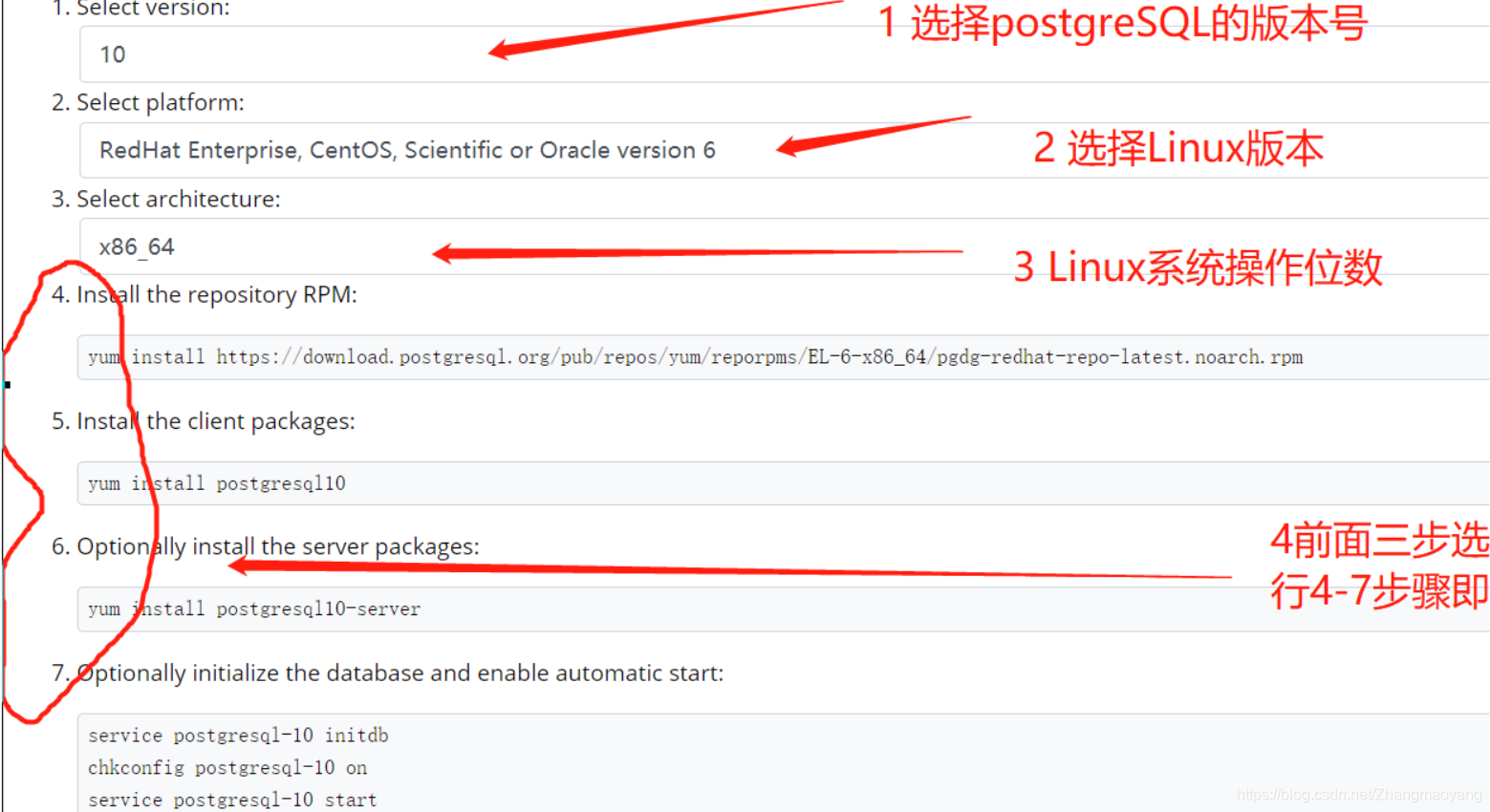
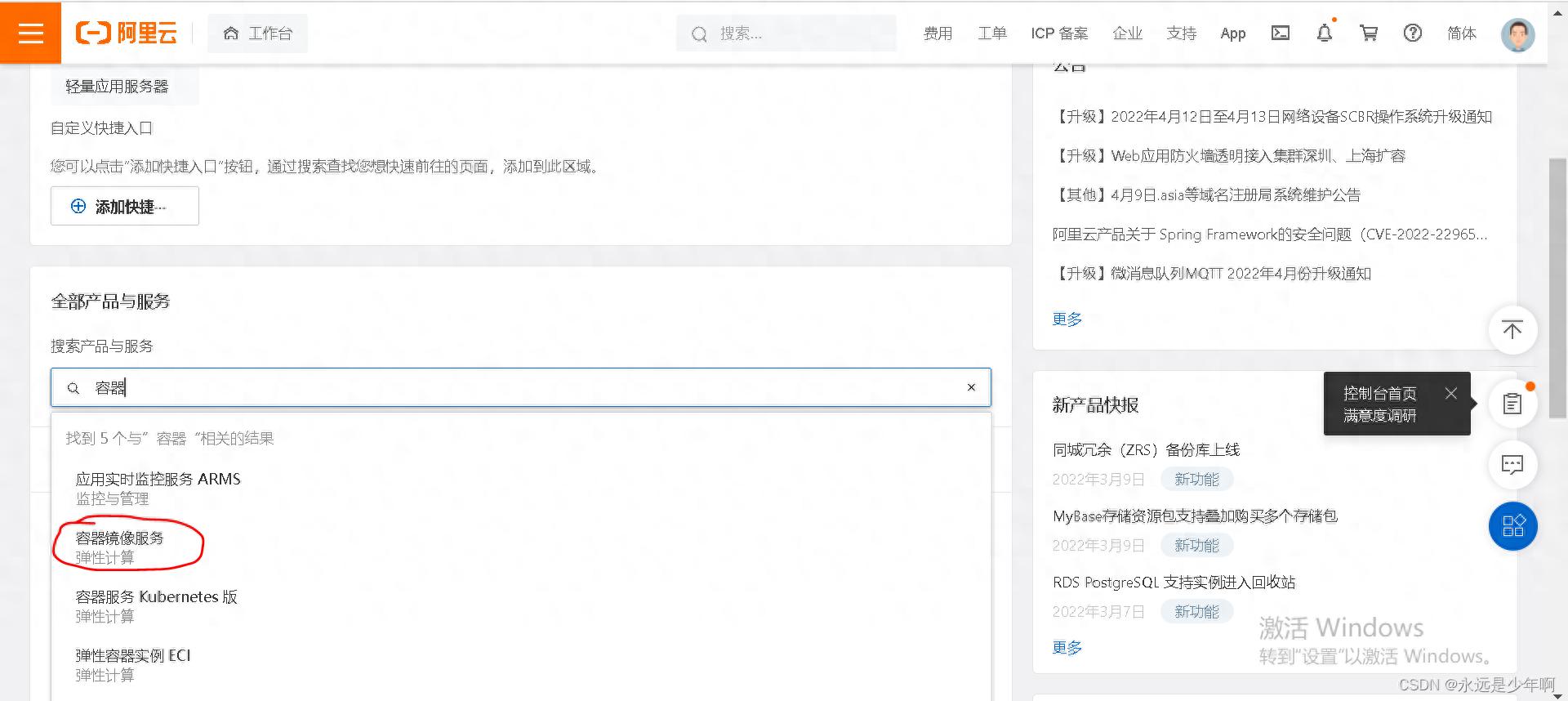
发布于 2026-02-28
摘要
域名:test.cc 服务器:Centos6.7、nginx/1.10.2 A服务器:192.168.8.142 B服务器:192.168.8.143 C服务器:192.168