
快下班的时候收到业务群投诉。
说财务那个报表,转了五分钟还在转。
没死,也没报错,就——卡在那。像等人又像迷路。
不是第一次了。
为什么我老在查 Swap
去翻监控。
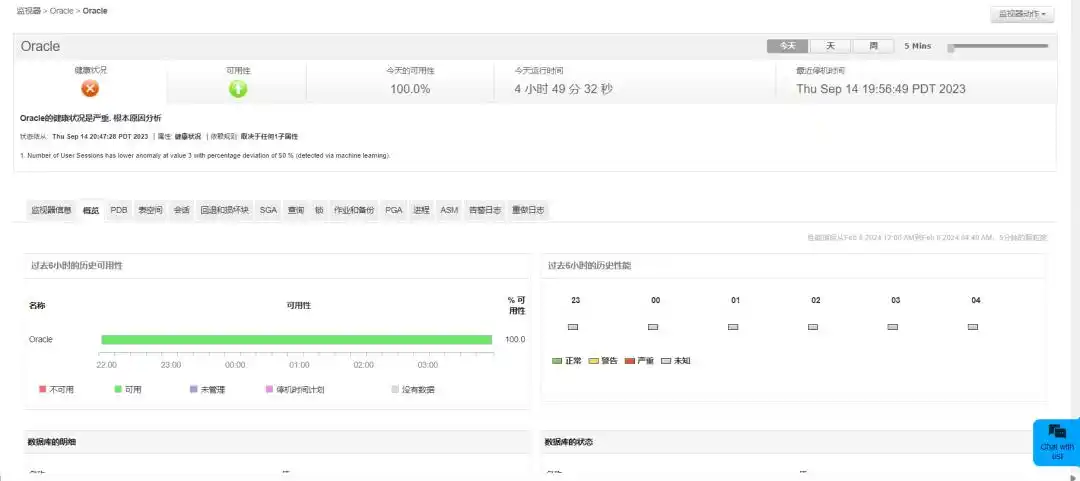
CPU 还行,负载曲线像老人心跳。内存,红了一半。
将 AWR 报告调取出来,其中 SGA 命中率为 67%。按照教科书所讲,若低于 90%那就应该采用吃药的方式来处理了。
然后我看到了 Swap。
被给予了128G的虚拟化平台,系统却认为不够,于是将20G塞进磁盘来假装内存。
磁盘和内存的差价是四个零。
业务不卡才有鬼。
那个时候,我突然间就这么想了,我们一整天都目不转睛地盯着IOPS、QPS、连接数、缓存命中率,就如同体检仅仅是测量血压一样。
可病人已经喘不上气了。
我们不知道 。
查询没变,数据变了
另一个坑。
是那条 SQL,它已经运行了三年时间,执行计划稳定得如同老干部一般,可是突然就在这周,它变得慢得像狗一样。
代码没改。索引没删。数据量也没涨多少。
查半天。
是选择性变了。
原来,性别字段之中,男性占比为一半,女性占比也是一半,然而现在,却有99.9%被标记成了“未知”。
优化器一看,这字段扫全表比走索引快。
它没错。是我们的业务逻辑把枚举值写崩了。
以前,DBA是依靠直觉去猜测这类问题的。如今,他们宣称正在教导AI学习进行“判断”,而这个“判断”的内容并非是修改SQL,而是判断“是否应该修改”,是这样的情况啦。
挺难的。
比慢更可怕的是看不见
有8亿用户是被OpenAI养着的,PostgreSQL的主实例并没有进行分库操作。
我读那篇分享时愣了很久。他们不怕吗?
后来懂了。他们不是不怕故障,是怕看不见的故障 。
慢的情况尚可忍受,断的状况也能够修复。最让人害怕的乃是那种,所有指标都呈现正常状态,然而唯有用户表示“不好用”。
监控图上绿油油。
业务电话响不停。
日志,别骗我
2026 年了,大家还在吵可观测性。
什么三支柱,什么统一平台。
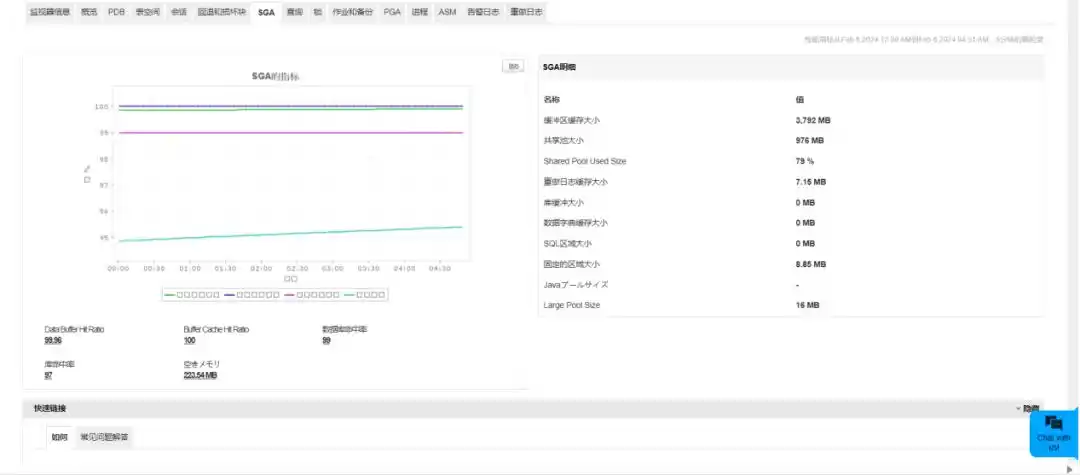
一句话是,我看,你敢不敢,在出事儿之际,对着一个数据库,将所有问题问完。
以前要跳三个控制台。指标在 A,日志在 B,链路在 C。
像三个证人各说各话。
现在有人把数据全塞进一列式数据库里,随便你用什么维度切。
代价是什么?
你得先去相信,那些具备高基数特征的,未曾有人进行聚合处理的,呈现出脏脏状态的原始数据,相较于任何漂亮的仪表盘而言,更具实用价值。
表空间会满,人心会慌
制造厂那个案例我发给团队了。
周四下午 16:33,业务报卡慢。
过了 12 分钟之后,DBA 进行远程介入。再过 8 个小时,内存从 128G 扩展到 220G,大页开启了,缓存被绕过去了。
晚上 12 点,业务恢复 。
这速度算快吗?
算。
可那八小时究竟如何呢,在这八小时期间,产线少了多少料,又喊了多少回“马上就好”呢。
监控工具不解决问题。
可人需要工具告诉他:问题在这,不在这,往那边看。
没人记得正确的查询
数据库这行有个挺悲哀的事实。
你处理了一百次危机,没人夸你。
但只要崩一次,所有人群聊里都是你的名字。
就像一个守门员,扑出一百个球是应该的,漏一个就上集锦。
所以老 DBA 都有点强迫症。
日志清理策略是需要设置的,然而却不敢采用全自动的方式,因为害怕会出现错误删除的情况。空闲连接是要掐断的呢,可是一旦掐错了,业务方面就会有人来骂。慢查询是要进行修改的呀,但是修改之后执行计划要是拐弯了该如何是好。
那些睡不着的阈值
以前设告警阈值靠猜。
CPU 80% 告。磁盘 85% 告。
过后发觉这实在是太愚笨了,业务处于低峰时段时,CPU即便飙升到90%也不会出现问题,可是大促期间,只要达到60%就开始出现抖动现象。
自适应阈值这个词我说了好几年。
其实就是系统自己学会“害怕”。
它会记得,上个月处于此刻时所发生的状况,上周二那一刻所发生的情形,昨天凌晨那段时间所发生的事情。
然后今天稍微有点不对劲,它就轻轻推你一下。
——“你要不要看一眼?”
表不是越大越好
有一回帮人看实例。
磁盘总空间 4T,用了 3.8T。
我说清理一下。他说不行,业务不让删,领导说加盘。
加盘当然能拖一阵。
可索引膨胀的问题,加盘治不好。
有个 PostgreSQL 的古老问题,遭遇到死元组占据一半空间的状况,哪怕 autovacuum 拼命运行到耗尽所有力气,也难以追上接连不断新产生的无用数据。
这就像一边倒垃圾一边扫地,垃圾车还堵在路上。
你给他一个大仓库有什么用。
我们到底在监控什么
写文档的人喜欢列指标。
CPU,内存,磁盘,IOPS,会话数,TPS。
表格画得整整齐齐。
可值班的人盯着屏幕在想什么?
他在想:今晚能不能睡整觉。
这个 SQL 抖了一下,是常态还是前兆?
那个连接池快满了,要不要半夜扩?
扩了明天要不要写复盘?
监控工具从来不问这些问题。
它只管报。
最贵的是上下文
买一套监控软件不贵。
招一个 DBA 也不贵。
贵的是什么。
属于那个 DBA 头脑中的内容:上个月曾发生过相似之事,那时是缘何如此;此 schema 乃老王于三年前构建的,他这人惯于采用 VARCHAR(255);那条运行缓慢的 SQL 在灰度环境未再次出现,是由于灰度数据分布与生产情形不同。
这些东西写不进文档。
现在有人说,试着把经验喂给大模型。
不是要它去编写SQL,而是要让它去学习DBA,学习DBA如何犹豫,学习DBA怎样排除,学习DBA在不确定之时如何不做出决定。
听起来有点科幻。
但总比让它写诗有用。
其实用户只想知道一件事
那些监控大屏,仪表盘红红绿绿。
领导路过觉得很高科技。
可真正出问题的时候,没人看大屏。
都在敲命令行。
都在翻最后的日志。
都在等那个最懂这套系统的人从会议里出来,说:我来看。
数据库是讲逻辑的东西。
可维护数据库的人,每天都在跟不讲逻辑的事打交道。
发生了数据倾斜,伴随网络抖动,出现半夜三点的告警,业务方面表示“以前均可运行为何如今却不行”。
我们不是科学家。
我们只是守门员。
球飞来的时候,扑出去。
没扑到的时候,承认是自己慢了。
然后明天接着站那。
Comments NOTHING