
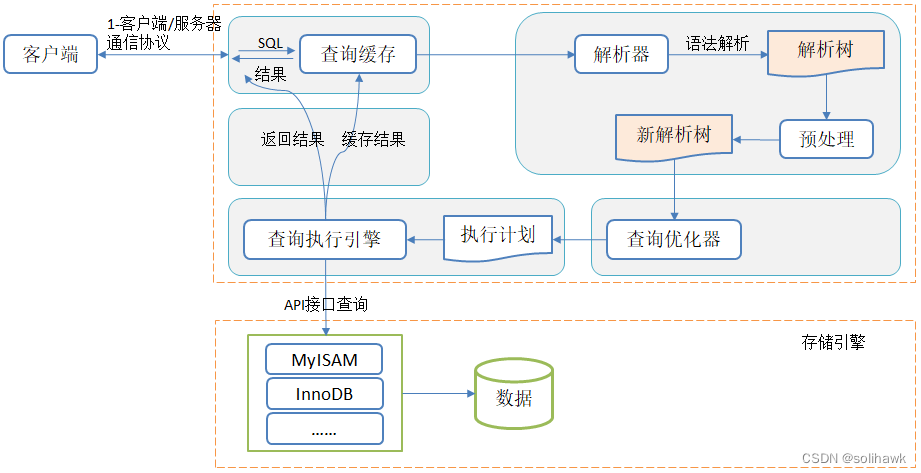
你数据库的统计信息,真的是按时进行最新更新的吗?存在许多出现慢查询以及突然变慢的系统,其根本原因都在这儿,那便是统计信息未能紧跟数据变化的步伐,优化器运用了陈旧过时的地图。
统计信息是什么
数据库当中的统计信息仿若一本城市交通指南,它记载下来每张表究竟存有多少行数据,每一个索引涵盖多少页,某一个字段的值分布匀还是不匀。这本指南为优化器指引道路选择,协助它遴选是进行全表扫描还是展开索引查找,判定首先连接哪一张表。在2023年某电商大促的那段时期呀,有一个核心订单表竟然从原本的500万行突然急剧增长到了2000万行,然而统计信息却没有及时予以更新,优化器始终按照500万行来规划路线了,最终致使复杂查询从原本的0.5秒转而变成了45秒,致使差点引发系统雪崩了呢。统计信息一旦过期,再好的数据库硬件也救不了性能。
MySQL的10秒判断法则
mysql> SELECT * FROM mysql.innodb_table_stats WHERE table_name like 't1'G
*************************** 1. row ***************************
database_name: test
table_name: t1
last_update: 2024-03-23 14:36:34
n_rows: 5
clustered_index_size: 1
sum_of_other_index_sizes: 2
对于MySQL而言,其存在一套会对统计信息自动执行更新操作的触发机制。当一张表之中的数据被修改的行数量,超出了总数据行数的10%的时候,MySQL便会去检查这张表上一次更新统计信息的具体时间。要是距离上一次更新的时间,已经超出了10秒,那么就会触发重新进行计算的操作。这样的一套逻辑,是从MySQL 5.6版本开始,就一直沿用至今的,并且默认会采样20个数据页,进而对全局进行估算。在2022年的时候,有某一个互联网金融平台做过相关测试,把采样的页数从20调整到了128,结果统计信息的准确性提升了大约37%,不过采集的时间也增加了差不多3倍。生产的环境当中,需在精度以及开销之间去寻觅平衡点,更新过后的统计信息,会被写入到mysql.innodb_table_stats以及mysql.innodb_index_stats这两张系统的表格当中,以供后续的查询能够直接读取。
vacuum threshold = vacuum base threshold + vacuum scale factor * number of tuples
PostgreSQL的自动真空阈值
analyze threshold = analyze base threshold + analyze scale factor * number of tuples
PostgreSQL借助自动真空机制来维护统计信息,默认参数autovacuum被设置为on,一旦表中更新、删除以及插入的记录数总和超过vacuum阈值,而此阈值通常是表行数的20%,那么后台就会唤醒autovacuum工作进程,这个阈值能够依据表进行单独设置,某银行核心库把大表的autovacuum_vacuum_scale_factor下调到0.05,这就意味着5%的变化便会触发收集。PostgreSQL会记录在最后一次自动收集之后,是否存有TRUNCATE操作之举,一旦存在,便会即刻触发新的统计信息。然而自动真空对于I/O密集型业务会产生影响,在2024年某物流系统处于高峰期时,自动真空频繁地被触发,致使磁盘I/O等待急剧飙升,最终将autovacuum_naptime从60秒调整至120秒,情况才得以缓解。
DB2与Oracle的同步异步之选
SQL> SELECT a.WINDOW_NAME,a.REPEAT_INTERVAL,a.duration FROM dba_scheduler_windows a WHERE ENABLED = 'TRUE';
WINDOW_NAME REPEAT_INTERVAL DURATION
------------------ ------------------------------------------------------- -----------------
MONDAY_WINDOW freq=daily;byday=MON;byhour=22;byminute=0; bysecond=0 +000 04:00:00
TUESDAY_WINDOW freq=daily;byday=TUE;byhour=22;byminute=0; bysecond=0 +000 04:00:00
WEDNESDAY_WINDOW freq=daily;byday=WED;byhour=22;byminute=0; bysecond=0 +000 04:00:00
THURSDAY_WINDOW freq=daily;byday=THU;byhour=22;byminute=0; bysecond=0 +000 04:00:00
FRIDAY_WINDOW freq=daily;byday=FRI;byhour=22;byminute=0; bysecond=0 +000 04:00:00
SATURDAY_WINDOW freq=daily;byday=SAT;byhour=6;byminute=0; bysecond=0 +000 20:00:00
SUNDAY_WINDOW freq=daily;byday=SUN;byhour=6;byminute=0; bysecond=0 +000 20:00:00
————————————————
DB2具备实时统计信息功能,于SQL编译阶段,要是发觉统计信息陈旧,便径直插入一回同步收集而后生成执行计划。此模式精准度超高,然而在OLTP高并发情形下,几十个会话同时编译新SQL之际,有可能争抢统计信息收集锁。某省级社保系统经实测,开启实时统计后,短查询编译时间由2毫秒增至18毫秒,最终变更为异步任务窗口,每日凌晨2点集中收集。自Oracle的11g起,自动统计信息收集任务被默认启用。该任务的调度窗口为这样的安排:在周一至周五的晚上10点运行、于周末全天运行。其阈值设定为表数据的变化超过10%,不过系统会将过去两周内刚刚收集过的表予以跳过,以此来避免重复劳动。
#禁用统计信息自动收集
SQL> EXEC dbms_auto_task_admin.disable(client_name=> 'auto optimizer stats collection',operation=> NULL,window_name=> NULL);
#启用统计信息自动收集
SQL> EXEC dbms_auto_task_admin.enable(client_name=> 'auto optimizer stats collection',operation=> NULL,window_name=> NULL);
#禁用维护窗口中统计信息收集
EXEC dbms_auto_task_admin.disable(client_name=>'auto optimizer stats collection',operation=>NULL,window_name=>'TUESDAY_WINDOW');
#启用维护窗口中统计信息收集
EXEC dbms_auto_task_admin.enable(client_name=>'auto optimizer stats collection',operation=>NULL,window_name=>'TUESDAY_WINDOW');
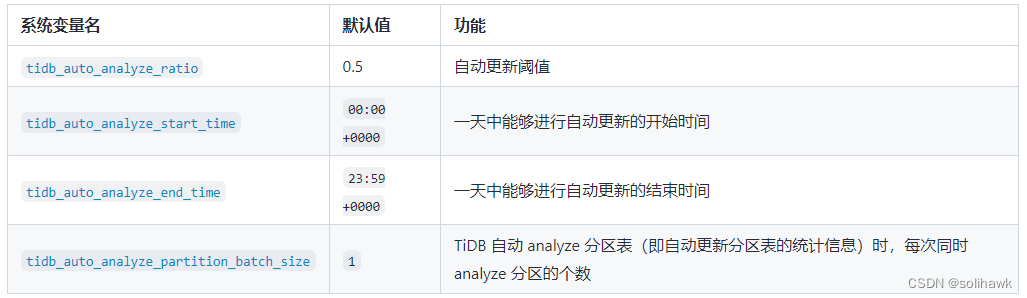
TiDB的混合阈值设计
TiDB针对分布式环境作出了特殊设计,自5.3.0版本开始,自动收集触发阈值默认设定为0.5,不过增添了两个保护机制,在表行数小于1000之时不会触发自动更新,以防止小表频繁出现抖动情况,并且仅在凌晨1点至6点其间开展后台自动采集工作,要把资源消耗控制在业务低谷期时间段。某互联网SaaS公司拥有200多个TiDB集群,每天自动更新大约15%的表,后台任务持续的时长约为40分钟。Stats-lease变量被他们用以控制统计信息于TiDB server节点处的缓存更新时间,默认每三分钟同步一回最新统计,以此保证查询不会读取到半小时之前的陈旧数据。
达梦与OceanBase的本土实践
Automatic maintenance (AUTO_MAINT) = ON
Automatic database backup (AUTO_DB_BACKUP) = OFF
Automatic table maintenance (AUTO_TBL_MAINT) = ON
Automatic runstats (AUTO_RUNSTATS) = ON
Real-time statistics (AUTO_STMT_STATS) = ON
Statistical views (AUTO_STATS_VIEWS) = OFF
Automatic sampling (AUTO_SAMPLING) = OFF
Automatic column group statistics (AUTO_CG_STATS) = OFF
Automatic reorganization (AUTO_REORG) = OFF
达梦数据库借助DBMS_STATS包达成统计信息管理,依靠自动收集依赖作业调度,管理员能够配置每周执行计划情形下,由系统自动识别上次收集之后数据变化超出15%的表而实现,某部委信创项目会把核心业务从Oracle迁移到达梦,然后沿用原本夜间统计信息作业以实现,以及切换之后TPCC性能保持在了98%水平而实现。OceanBase具备兼容MySQL模式,与此同时还给自身提供那自行的收集策略,它的系统包会每日挨个对租户内部所有的表做轮询操作,依靠内部视图去记录所改动的行数,一旦行数超过1000并且变化率超出10%的话便加入汇集队列之中。在2025年之时的那某银行关于双11大促阶段期间,OceanBase主动把自动统计任务进行屏蔽,会全部转变为人工触发形式,以此来保证促销时段不会有零额外负载的问题出现。
自动更新不是万能解药
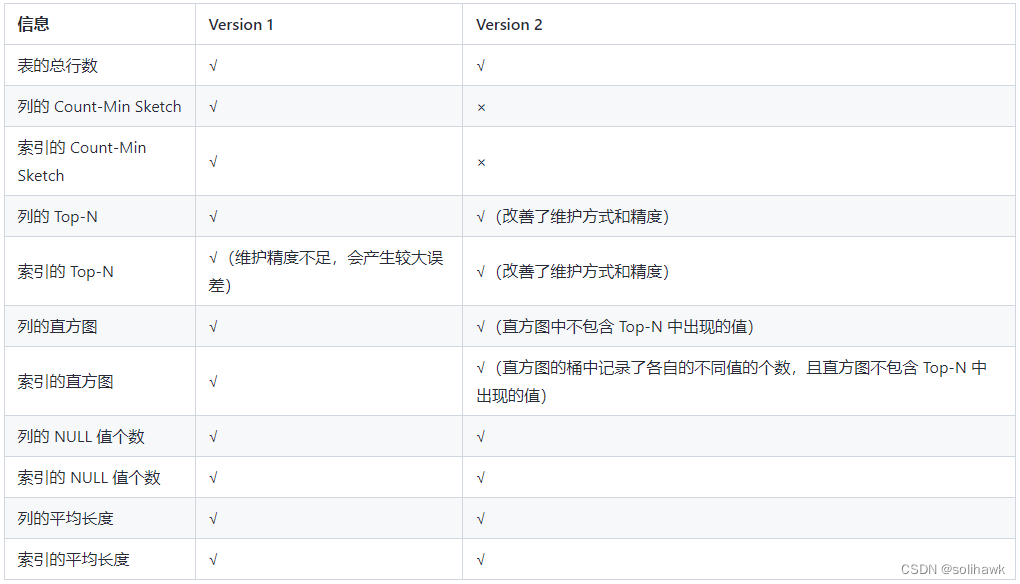
统计信息自动更新机制的本质是预设规则,它没办法覆盖所有业务场景,MySQL的10%阈值对于百亿行大表而言依旧偏激进,并且每次自动采集所耗费的时间有可能超过20分钟,PostgreSQL的自动真空在高版本里虽然已对I/O放大问题进行了优化,可在合并大量死元组的时候仍然可能出现锁表现象,传统商业库和开源库的策略差异显著,前者为求稳默认关闭自动收集,后者为求快默认开启。进行实际的运维操作时,需依据表的维度来定制对应的策略,对于核心流水表,要设定较低的阈值,并进行高频次的采集,而配置表由于几乎不会发生变动,所以采用手工方式来固定相关的统计信息。
你的业务系统当中,有没有什么时候曾因统计信息过期致使出现过较为严重的故障?那个时候是就凭借调整自动采集策略给解决掉的,抑或是完全变成手动维护的方式?欢迎在评论区域分享你遭遇问题的经历,点赞并且转发以便让更多同行业的人避开这些隐患。
Comments NOTHING