
身为一名于企业级运维范畴历经多年历练打拼的工程师,我深切明白“基础不稳,地面晃动”这般的道理呀。
多数情形下,软件上线完毕后呈现出性能方面的瓶颈状况,众人的首个反应是“增添机器”,然而却将服务器自身的“体质”以及“调教”给忽视掉了。
今儿,咱从实战层面出发,深度解析服务器性能调优的三大关键环节,其一为配置选型,其二乃负载分析,其三是内核参数调优。
一、 服务器配置选择:基于压测,而非臆测
场景:你准备上线一个订单业务,需要采购服务器。
是径直走向具备128核、512G内存这般配置的堪称“顶配怪兽”的设备,还是先以小规格作为起始开端,是这样的选择?
備好:一整套完備的壓力測試工具,像ab、JMeter或者wrk,還有一個等待測試的軟件環境。
分步实操:
许多刚开始接触的同学,会掉进一个错误的区域,那就是尝试去寻觅一个能够用来计算服务器配置的“万能公式”。
其资源消耗模式,是由软件的业务逻辑以及代码质量直接决定的,所以这几乎是不可能的。
两个接口,均处于同一个程序里,一个是查询订单的接口,另一个是创建订单的接口,它们对于CPU以及磁盘的消耗,呈现出截然不同的状况。
我的经验是:从低配起步,用数据说话。
将一台配置不高的服务器申请下来(像那种具有4核CPU且内存为16GB的),把你的整个应用链路部署妥当(涵盖后端服务以及数据库等方面),之后开展压力测试。
以我们手头的这个订单业务为例,压测结果如下:
服务器配置:4核CPU、16GB内存、机械磁盘。
压测结果呈现的状况为,能够稳定地支撑50的并发数目,且吞吐量符合标准要求;然而,一旦并发量持续不断地增多,接口便会开始出现超时而引发报错的情况。
强标签内的资源监控情况为,处于压测期间时,CPU的使用率快要接近七成五,内存的使用率比五成要低,带宽的使用率也比五成要低,除了日志部分之外基本上不存在磁盘读写的情况。
操作目的与排错思路:
这个结果就是最宝贵的选型依据。
以下是反向推导得来的情况:内存充裕到了严重的程度,带宽充裕的程度也很严重,在这样的状况下,CPU成了主要的瓶颈所在。
所以,有这样一台服务器,它具备4核CPU、8GB内存以及5Mbps带宽,从理论上来说,是能够满足50并发的业务需求的,其中内存和带宽使用率能够接近100%,然而CPU必须要留有余地,以此应对突发流量,建议使用率要低于75%。
注意事项:明确必须要把整个服务链路,像后端以及数据库,一同进行压测。
有一回我碰到个情况,后端的服务器,其CPU一直处于很低的状态,然而数据库的服务器那儿,I/O却被搞到崩溃,最终经过仔细排查才明晰,原来是后端代码当中,有一条SQL查询采取了全表扫描的方式。
如果单独调优后端,问题永远无法解决。
二、 服务器负载分析:四大核心指标
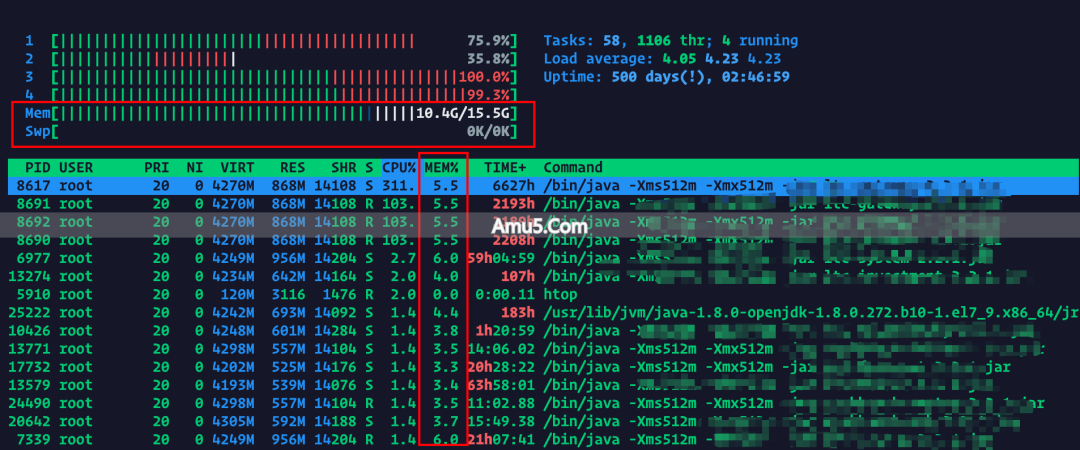
yum install htop -y拿到服务器后,我们需要精确分析其运行状态。
我们着重关注四个指标,分别是,CPU使用率,内存使用率,磁盘I/O,平均负载。
1. CPU使用率
htop操作目的:判断CPU是否繁忙,是否有扩容需求。
执行细节方面,我以强烈的态度进行推荐,所推荐的是htop命令,它在直观程度上相较于top命令而言,是更具直观性的。
安装后直接输入 htop。
重点注意:你会看到每个CPU核心的独立进度条。
一台具有4个核心的服务器,只有在这样的情况下,即所有核心的使用率都一直持续超过75%这个程度时,才能够判定CPU整体负载过高。
倘若仅仅是一核处于满载状态,而其余部分呈现空闲状况,那么这属于单线程进程的调度相关问题,并非是整体性能存在不足的情况。
2. 内存使用率
操作目的是,对物理内存使用状况予以监控,要极其严格地防范使用虚拟内存也就是 Swap。
这其中的 执行细节 是,于 htop 界面的顶部之处,能够以清晰明了的状态看到物理内存以及 Swap 的使用量情况。
排错思路:Swap使用率必须保持为0。
如果一旦察觉到Swap处于被占用状态(大于零),那就表明物理内存已然耗尽,一部分程序与代码或者数据被交换到那些速度极为缓慢的硬盘之上,如此一来便会致使整个系统的响应变得迟缓。
此时应立即增加内存或排查内存泄漏问题。
3. 磁盘I/O

,操作目的:剖析磁盘读书写字的压力状况,特别是针对数据库以及日志系统而言。
执行细节:运用,使用,采用,运用那,即,就是那个,那个名为,被叫做,被称作,被称做,被唤作,被叫做,被称为,被称作,被称呼为,被叫做的,被称作的iostat -x 1命令,去持续查看。
要把重点放在,%util,也就是设备I/O请求时间占比上面,以及,await,即是I/O响应时间那里。
如果 %util 接近100%,磁盘就是系统瓶颈。
4. 平均负载 (Load Average)
操作目的:综合判断系统是否处于“过载”状态。
细节执行方面,htop命令会显示load average: 1.5, 2.0?, 1.8这三个值,uptime命令同样也会显示这三个值,它们分别代表1分钟的平均负载,5分钟的平均负载,以及15分钟的平均负载。
重点注意:这个值的“及格线”是小于CPU核心数。
yum install sysstat -y例如4核CPU,平均负载应小于4。
鉴于要去应对突发状况,我们一般是要求它维持在核心数的百分之七十五以下,也就是小于三。
要是平均负载始终长时间超4,那就表明CPU始终处于排队开展任务的情形,必然得进行扩容或者优化程序。
三、 内核参数调优:释放系统潜能
# 查看磁盘总体读写情况, 1代表每1秒读取一次数据
iostat -x 1仅仅硬件与负载分析属于第一步,若要在高并发场景当中稳如泰山,那就必定得针对Linux内核予以调优。
这主要是针对前端代理,比如说Nginx,另外还针对后端应用,以及数据库服务器。
1. 单个进程最大打开文件数

场景呈现为,处于高并发之时,存在一个Nginx或者Java进程,此进程要同时跟成千上万个客户端构建连接,并且每个连接算得上是一个文件句柄。
要是系统默认值偏小,而此默认值通常被设定为1024,那么就会出现报错情况,报错内容为 too many open files。
配置:
临时生效(当前会话):ulimit -n 65535
具备永久生效特性:对 /etc/security/limits.conf 文件予以编辑,紧接着进行追加操作:
soft nofile 65535
hard nofile 65535

与此同时,要是运用Systemd对服务予以管理,那么在服务配置文件当中还得添加 LimitNOFILE=65535。
2. TCP 相关设置
有这样一个场景,在处理高并发网络请求这个事情的时候,系统很有可能会存在数量众多的处于 TIME_WAIT 状态的连接,这些连接会占用掉端口以及内存,进而致使新的连接不能够建立起来。 / 当处于处理高并发网络请求的场景时,系统有可能出现大量处于 TIME_WAIT 状态的连接,这些连接对端口造成占用同时耗费内存,使得新的连接无法成功建立。
操作步骤如下,首先,找到并对名为“/etc/sysctl.conf”的文件进行编辑操作,接着将要添加的下述内容添加上去,之后运行“sysctl -p”这个命令从而让所做的配置生效。
# 允许将TIME-WAIT状态的socket重新用于新的TCP连接
net.ipv4.tcp_tw_reuse = 1
# 开启TCP连接中TIME-WAIT sockets的快速回收,这个选项在NAT环境下可能导致问题,新版内核已弃用,谨慎使用
# net.ipv4.tcp_tw_recycle = 0 (建议保持关闭)
# 表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间
net.ipv4.tcp_fin_timeout = 30
# 端口范围,影响单机对外发起连接的能力
net.ipv4.ip_local_port_range = 1024 65000
# 当网络接口接收数据包的速率大于内核处理速率时,允许送入队列的数据包最大数目
net.core.netdev_max_backlog = 5000
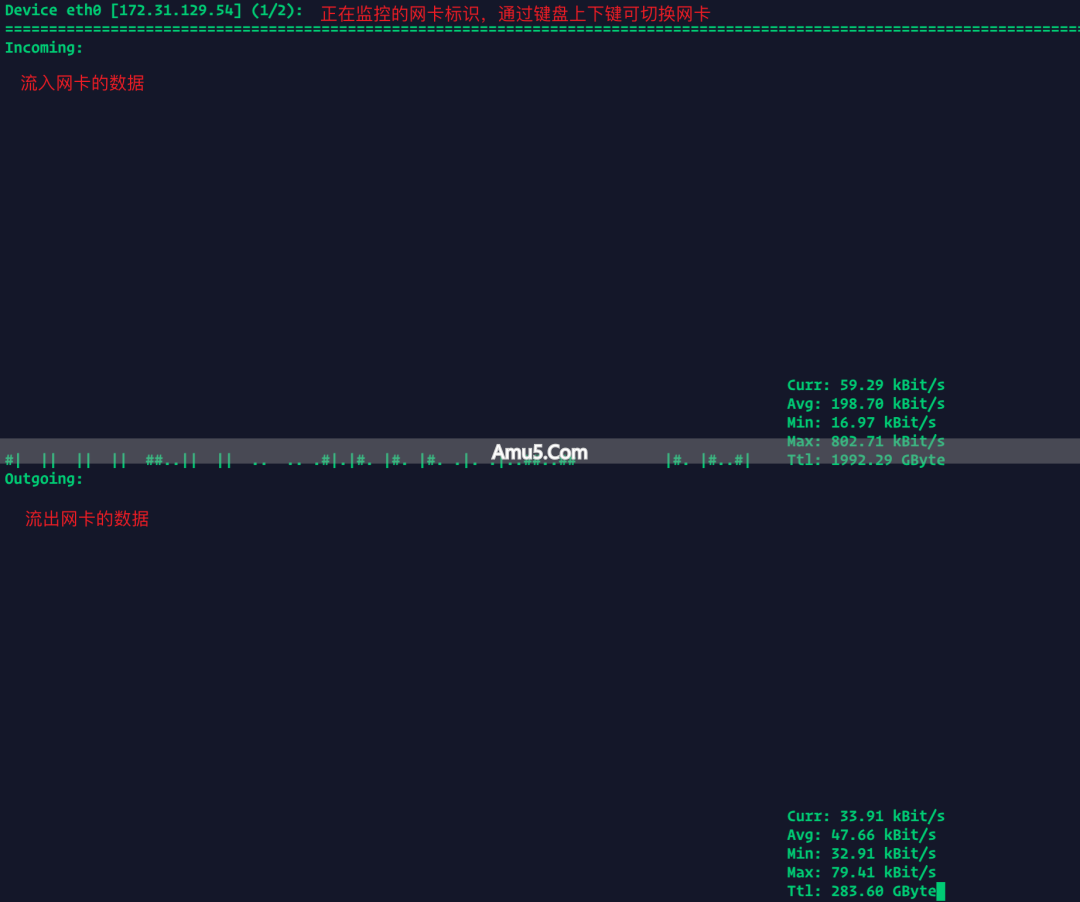
yum install nload -y总结
服务器性能调优可不是一下子就能完成的,它是这样一个过程,先是进行测试,接着展开分析,随后实施调整,之后又再次进行测试,这是一个形成闭环的过程。
nload于压测里依据科学去选定型号,借助 htop、iostat 之类的工具精准确定 CPU、内存、I/O 以及平均负载的阻碍之处,进而进行有针对性的内核参数细微调整,每一个步骤均需要严谨的数据给予支撑以及实践方面的经验。
牢记,并非最贵的服务器就必然是最为合适的,唯有经过充分“调校”的系统,方可在高并发的洪流之中稳如泰山,坚不可摧。
希望今天的分享能对你的实战有所帮助。
Comments NOTHING