
销售历史表的分区实战:从文件组规划到SQL访问透明化
于生产环境里头,伴随业务数据的积累增多,单表数据量变得过大,常常会成为数据库性能方面的瓶颈所在。
拿销售记录表来说,在数据量抵达数亿级别之际,就算构建了合理的索引,查询操作的响应时间,以及写入操作的响应时间,都有可能会急剧地上升。
此时,表分区是一种有效的物理存储优化手段。
它把一个逻辑规模很大的表,拆分成多个物理层面较小的表不过对于上层的应用来讲它是透明的,程序员依旧把它当作一张表来开展操作。
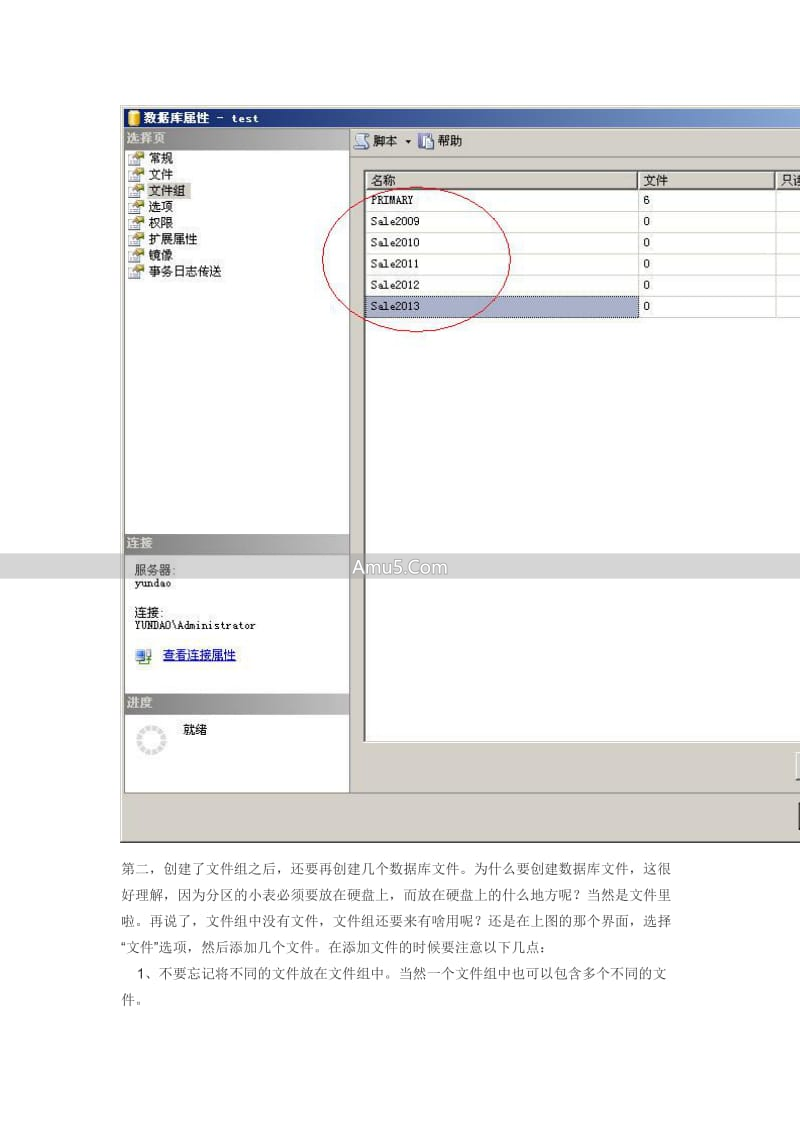
第一步:库表设计与文件组规划
在创建分区表之前,首先需要在数据库层面规划好物理存储结构。
为了达成便于管理以及提升I/O性能的目的,我们应当事先创建文件组,并且要把不一样的物理文件分配至不同的文件组当中。
比如说,依据时间范围,就像年份那样,把销售表划分作为5个小表,这5个小表分别对应着5个不一样的文件组。
在SQL Server中,可以通过以下步骤实现:
于数据库属性里头,进入“文件组”选项,针对每个给定年份(2010、2011、2012、2013、2014),添加与之对应的文件组,像 FG_Sales_2010、FG_Sales_2011这般。
首先,切换到“文件”选项,接着,针对每个文件组,添加至少一个数据文件,也就是.ndf。
比如,给 FG_Sales_2010 增添 Sales_2010_data.ndf 文件,从而指定它的初始大小,明确其自动增长策略,确定物理路径。
把不一样的物理文件,分散放置到多种不同的磁盘或者存储卷上面,能够明显地降低I/O争用,这是让分区表性能得到提升的基础所在。
第二步:创建分区函数与分区方案
定义分区函数的是,数据怎样被划分至各异分区里的方式,而这属于分区操作的关键逻辑。
创建分区函数,定义按照年份范围分区
CREATE PARTITION FUNCTION pf_SalesByYear (datetime)
AS RANGE RIGHT FOR VALUES (
'2011-01-01',
'2012-01-01',
'2013-01-01',
'2014-01-01'
);
这儿运用 RANGE RIGHT 来表明边界值归属于右侧分区,以此保证数据划分的精确性。
该函数将数据划分为5个分区:<=2010、2011、2012、2013、>=2014。
创建分区方案,将分区函数映射到之前创建的文件组上:
CREATE PARTITION SCHEME ps_SalesByYear
AS PARTITION pf_SalesByYear
TO (FG_Sales_2010, FG_Sales_2011, FG_Sales_2012, FG_Sales_2013, FG_Sales_2014);
这样,每个年份的数据将物理存储在其对应的文件组中。
第三步:创建分区表并优化索引
在分区方案上创建表,指定分区列:
CREATE TABLE dbo.Sales (
SalesID bigint IDENTITY(1,1) PRIMARY KEY NONCLUSTERED,
SaleDate datetime NOT NULL,
ProductID int NOT NULL,
Quantity int,
Amount decimal(18,2)
) ON ps_SalesByYear(SaleDate); -- 指定分区列
索引优化要点:
在分区表之上进行创建索引的操作之时,较为适宜地要去运用那个 ON ps_SalesByYear(SaleDate) 选项,从而达成让索引能够与表实现对齐的目的 ,这便是所谓的对齐索引。
提升分区切换等操作,比如代码为“SWITCH”的这类操作的效率,需要对齐索引,并且对齐索引还能简化管理。
聚集索引的挑选:在以按时间作查询的主要情形下的场景,会设想把SaleDate当作聚集索引的键,并且联合ProductID等构建成复合索引,以此涵盖常用的查询。
CREATE CLUSTERED INDEX CIX_Sales_SaleDate ON dbo.Sales(SaleDate, ProductID)
ON ps_SalesByYear(SaleDate);
第四步:事务控制与写入优化
对于高并发写入场景,分区表本身不增加编程难度。
程序员只需执行标准的 INSERT 语句:
INSERT INTO dbo.Sales (SaleDate, ProductID, Quantity, Amount)
VALUES ('2015-01-01', 1001, 2, 200.00);
数据库引擎会根据分区函数自动将数据路由到对应的物理分区。
但在高并发事务中,需注意:
维持事务简洁,防止在一个事务里更新多个历史分区,避免出现锁升级以及死锁,以此来避免跨分区事务。
利用表值参数去进行批量插入:针对批量写入这种情况,采用表值叁数或者SqlBulkCopy,还要指定TABLOCK提示,可以降低日志开销。
第五步:性能调优与分区裁剪
分区表最大的性能优势在于分区裁剪。
当开展查询操作,条件里头含有分区列这种情况,就像 SaleDate 这样,此时SQL Server的查询优化器,它能够凭借自身能力自动去判断,仅仅扫描与之相关的分区,并非进行全表的扫描。
此查询只会扫描 FG_Sales_2014 对应的物理分区
SELECT SUM(Amount) FROM dbo.Sales
WHERE SaleDate >= '2014-01-01' AND SaleDate < '2015-01-01';
通过查看执行计划,可以验证是否发生了分区裁剪。
要是查询计划里依旧扫描了全部的分区,就应当去检查查询条件是不是针对分区列开展了函数运算,而这般做可是会致使裁剪失去作用的。
第六步:备份恢复与主从复制考虑
分区表在备份和恢复方面提供了灵活性:
关于文件组备份,存在这样一种情况,能够专门对包含最新数据的活跃文件组(诸如 FG_Sales_2014)单独进行备份,另有一系列历史静态文件组(像 FG_Sales_2010),其只需备份一回,如此便会极大程度减少备份窗口。
需求为归档,若是有此需求,那么对于该需求而言,可运用SWITCH操作,此操作能把旧分区即刻切换至另外一个归档表,借此达成数据的不停机迁移,即零停机迁移。
支持复制:分区表对事务复制以及 Always On 可用性组均有着完全的支持。
于进行配置复制期间,要保证订阅服务器那儿的表结构,此处表结构含分区方案,跟发布服务器保持一致,进而防止复制出现失败情况。
第七步:分库分表与未来扩展
数据量大于单个实例所能承受之力时,那么分区表能够平稳地转变至分库分表的这种架构这儿呢。
比如说,能够把最先的历史分区(像是2010年的数据那般)借助备份恢复这种方式转移进历史库里头,接着经由分区合并或者删除行为来释放当下数据库的空间。
就应用层而言,能够借助数据库中间件,像 ShardingSphere 或者 MyCat,来针对多个数据库实例予以透明路由,以此达成水平扩展。
运用上述这些步骤,我们达成了对于销售表的高效能物理存储,并且还保证了业务逻辑的毫无缝隙兼容性,给生产环境的平稳运行供应了可靠的保障。
Comments NOTHING