
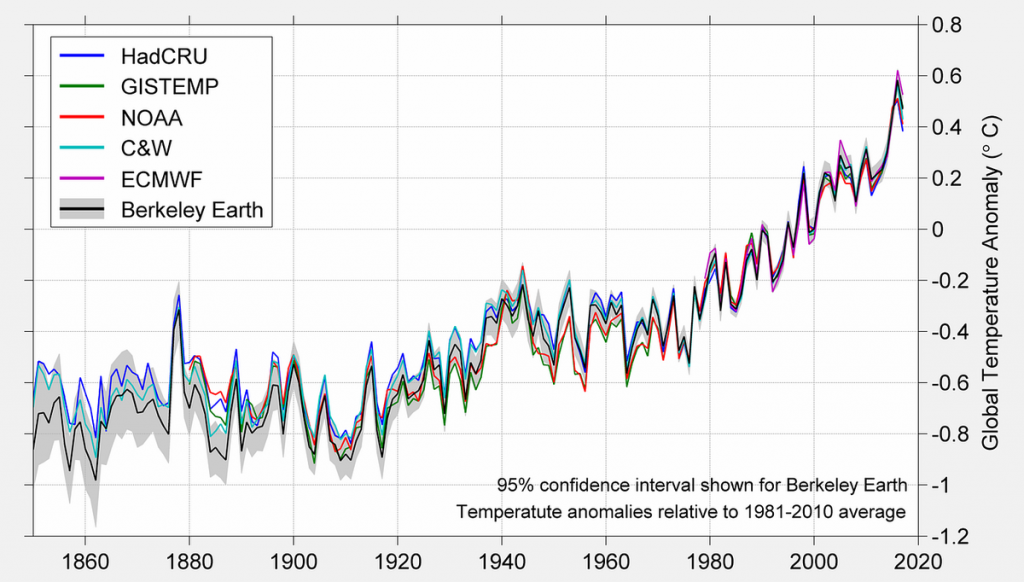
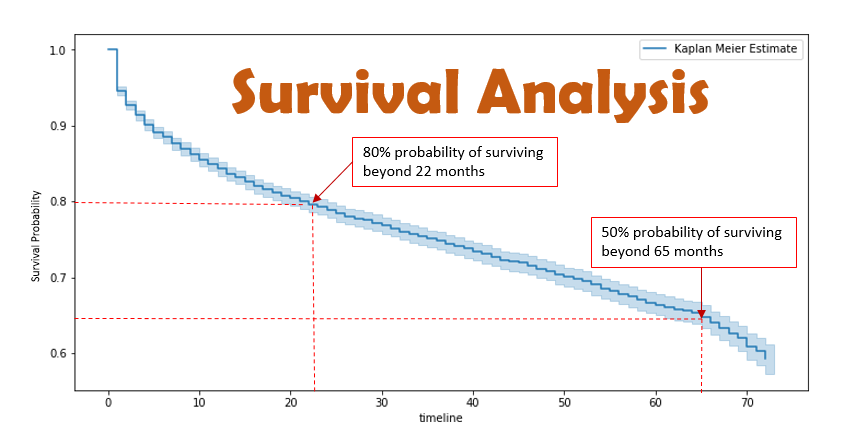
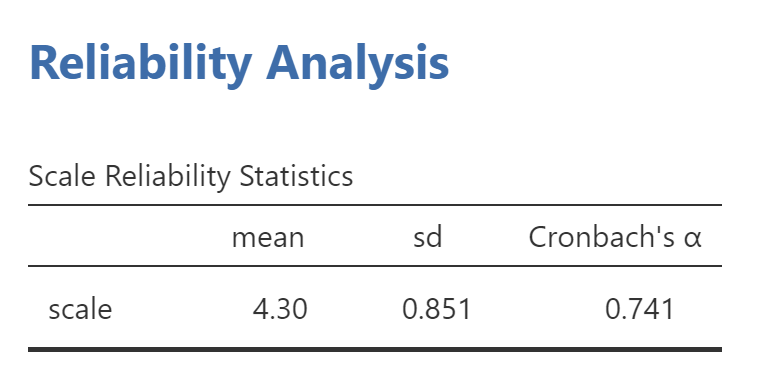
于你手上所拥有的数据分析工具而言,其远较你心里所想象的更为强大,并且还远较你脑海中所认为的更具局限性。其中最为关键之处在于,你是不是真真切切地清楚究竟是在什么样的场景之下应当拿起哪一把锤子!

描述统计不是报数字而是讲故事
针对数据分析刚开始最基础的描述统计这一动作,在2025年的时候,某电商平台针对第一季度退货率展开分析,并非仅仅计算平均退货率3.2%这个数值。他们对不同品类的中位数以及众数进行了拆解,其中女装类目众数高达15%,这表明相当多的用户存在习惯性多拍商品试穿之后再退款这样的行为,而这种情况直接促使了预售模式进行调整。
只凭借平均数会被极端值所误导,产生偏差。有一个从事连锁餐饮业务的品牌,在针对门店客流展开分析的时候,察觉到这样一种情况,即在周末的时候,单日客流的均值是1200人次,然而周一至周四的实际客流,大部分处于600至800人次的范围之内。基于如此分布状况,该品牌将员工排班方式调整为动态调配模式,仅仅上海地区的二十家店铺,在一年的时间里,就节省下了多达四百多万的人力成本。
统计描述的实质是对信息的压缩,借由直方图呈现用户年龄具体分布状况,依靠箱线图揭露异常的订单金额情形,凭借标准差去量化生产线良品率的波动幅度,这些图表实际具备的价值并非告知他人数字究竟为何,而是能够令决策者迅速洞察问题潜藏的位置。
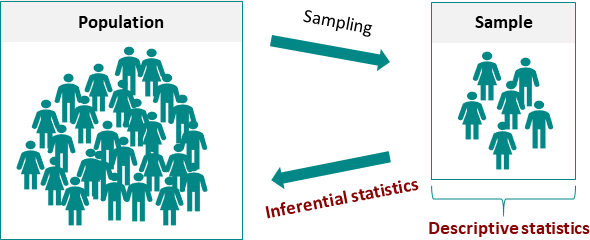
推论统计是在用样本赌全局
做用户调研,互联网大厂很少能访问全部用户。在2026年1月,某短视频平台想要对相关新版本满意度的状况变化进行了解,之后抽样了五千名活跃用户。经过计算置信区间,他们发现整体满意度处于4.1分到4.3分区间内,然而年轻用户群体明显低于老用户,而且这个差异顺利通过了显著性检验。

最怕假设检验出现采样偏差,去年有个医疗公司测试新的检测试剂,实验室得出的数据表明灵敏度提高了20%,然而投放到社区之后出现效果远没有达到预期的情况,在复盘的时候发现早期样本集中在三甲医院,这些患者病程偏早,重新进行抽样后,检验结果才与真实场景相吻合。
进行推论统计时,一定要坚守住随机性原则,不少产品经理热衷于在 App 内通过弹窗来征集反馈,然而这种自愿样本常常会使极端意见被放大,实际上,能够反映总体情况的是依据用户 ID 哈希值进行均匀抽样所得到的那一批人,即便样本量仅仅只有三百个。
回归分析不止看斜率更要看残差
某共享出行平台,对订单量与补贴力度之间的关系展开研究,简单线性回归表明,每增添一元补贴,订单量便会上升八千单,看上去颇为划算,然而,在进行残差分析之后,他们发觉,当补贴超过五元之时,残差开始系统性地呈现为正,这意味着存在非线性效应,并且实际边际收益远远高于前期。
提到多元回归,需要警惕共线性问题。有一家家电企业,在分析冰箱销量与广告投放之间的关系时,将电视广告、网络视频广告、线下海报同时放置进模型之中,然而结果却是,三个系数都不具备显著性。后来经过发现,这三类投放时间呈现出完全同步的状态。此家电企业去掉其中两个之后,单一渠道的系数变得显著,并且呈现为正,有这样的情况出现。
回归所具备的价值并非在于去证实因果关联,而是旨在对影响权重予以量化。银行的风控模型里,收入与负债率有着高度的相关性,倘若进行单变量回归,就会对负债率的影响做出过高估值。在把两者同时放置进模型之后,收入系数降低了四成,这种情况才属于真实的贡献度剖析。
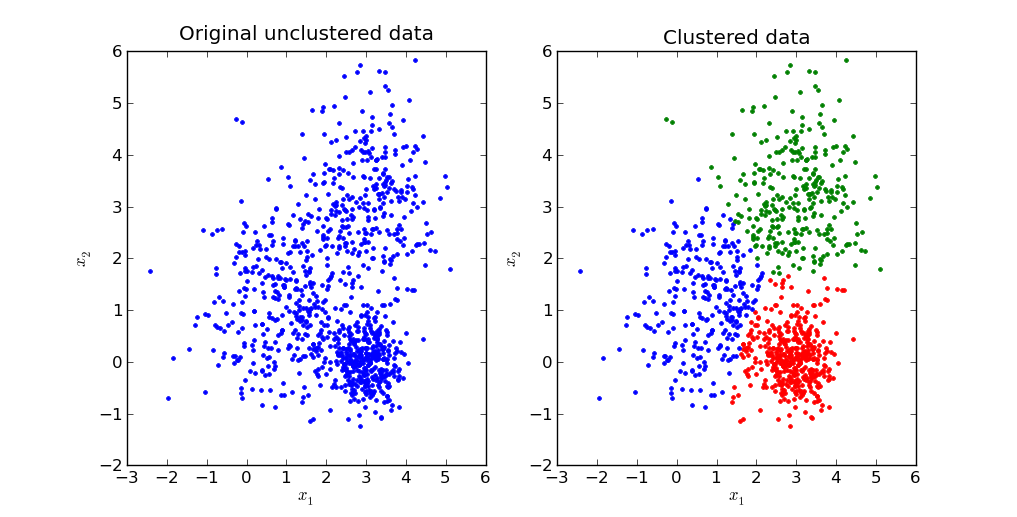
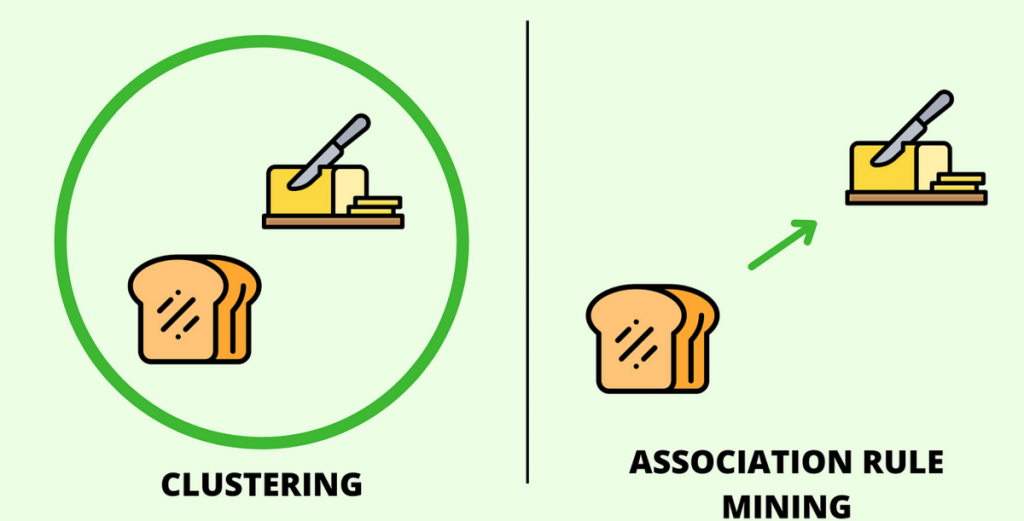
聚类分析结果取决于距离定义
有家母婴品牌想着将两千万用户进行分群,运用常规的K-means依据消费金额以及频次来聚类,进而获得高价值、中价值、低价值这三个群体,然而运营部门拿到之后却不清楚该怎样加以针对性施策,随后改用基于购买品类偏好去做层次聚类,划分出了羊奶粉偏好组、有机辅食组、纸尿裤囤货组,每组的话术以及选品均是完全定制的。
实时推荐在电商大促期间被运用,其采用的是在线聚类算法。在2025年双十一时,某平台针对用户行为聚类进行每五分钟一次的更新,将正在浏览婴儿车的用户以及浏览安全座椅的用户归为同一类,这是由于他们均处于孕期或者刚生育的阶段。这种动态分群使得推荐点击率提升了22%。
对聚类而言,关键之处并非算法有多先进,而是在于所选取的特征是否正确。借助RFM模型三个维度所开展的聚类内在地适宜用于进行客户价值分层,运用浏览历史实施的聚类则适合用于开展协同过滤。倘若更换一组特征,那么所得到的群组含义便会全然不同。
因子分析和主成分本质都是降维
一份有着四十题的消费者态度量表,要是直接去做回归的话,将会出现严重的多重共线性。某汽车品牌在开展车主忠诚度研究之际,先是用因子分析,从中提取出品牌认同、售后满意、产品性能、价格感知这四个因子,接着再凭借这四个因子的得分去预测复购意愿。该模型的解释力从百分之三十一提升到了百分之五十八,并且每个因子都具备明确的业务含义。
主成分分析对信息压缩比例更为关注,有某基因测序公司,面对两万个表达量指标,运用PCA提取前五个主成分便可解释74%的变异,后续的聚类以及可视化均在这五维空间开展,原本根本无法绘制的超高维数据变得能够操作了。
不过这两者并非是那种能解决一切问题的神奇药物,因子分析对于变量之间有着确实需要存在潜在结构的要求,要是强行去使用它,就会把那些随机产生的噪声也一并打包成没有实际意义的因子,主成分属于原始变量的线性组合形式,其在解释方面天生就比原始指标要弱一些,不要仅仅是为了降低维度就去进行降维操作。
分类预测模型要区分解释和预测
信贷审批里判别分析仍然活跃着,某消费金融公司以年龄、收入、职业、历史借贷记录开展线性判别,进而生成一个综合风险分数,这个函数系数大小直接反映出变量对于区分好坏客户的重要程度,业务部门极易理解且接受。
具有最强可解释性的是决策树,在2025年的时候,有某保险公司针对车险理赔反欺诈展开行动,借助决策树识别出了几个高危特征组合,即夜间出险并且刚续保以及小型维修厂,像这类案件的欺诈概率乃是平均水平的七倍,他们将这条规则直接写入系统,无需调用黑盒模型便能够实现拦截。
可在预测准确率这个方面,简单模型常常会输给复杂集成学习。于实际应用当中,有许多团队采用了折中方案,将逻辑回归或者判别分析用作可解释的底线模型,把XGBoost或者随机森林用于追求极致精度,按照场景需求进行二选一或者同时进行部署。
于你工作里面,最为经常去调用的是这十七种方法当中的哪一种呢,它于哪一个具体的项目里面帮助过你或者给你带来过困扰呢,在评论区去聊聊你自身的实战案例,从而可以让更多的人能够减少走弯路的情况出现了。
Comments NOTHING