

无监督学习的范式重构:从压缩理论到规模化突围
审视人工智能的演进轨迹期间,监督学习就着其清晰的优化目标,以及能够被量化的性能提升表现,长久地处在研究跟产业应用的核心位置上。
然而,存在着一个根本性的悖论,这个悖论一直悬而未决:人类的学习过程不怎么依赖海量的标注数据,动物的学习过程也极少依赖海量的标注数据,可是人类与动物还是能够从观察里提炼出世界的结构化知识句号。
过往的数年间,伴随BERT,与扩散模型,以及GPT系列模型的突破 ,产业界,和学术界,开始再次审视无监督学习的核心价值。
在对压缩理论作出深度剖析之后,又对VC维度给出细致探讨,其后进行规模化实验,在这一系列行为过后,我们就此得以看见一条通往通用人工智能的清晰路径。
行业背景:监督学习的边际红利递减与无监督的必然崛起
过去十年当中,深度学习呈现出高速发展的态势,其本质是建立在监督学习所带来的规模化红利的基础之上的。
Imagenet的被标注图像,机器翻译的平行类型语料,人工进行标注的指令微调数据,共同构成了模型性能得以提升的燃料。
然而,当模型参数渐渐往万亿级别逼近时,高质量监督数据的采集成本呈现出指数级的上升态势,并且标注质量自身变成了瓶颈。

更为关键的是,仅仅是单纯的这种监督学习,往往其所能达成的仅仅是去拟合输入以及输出之间的那种表面的映射关系,而很难能够触碰到数据生成所蕴含的底层结构。

于此同时,以GPT为代表的大语言构成的模型,展现出一种令人惊叹的能力。这种能力是,即便只是通过下一个词的预测,而这是一种典型的无监督学习目标,模型却也能够涌现出语法能力,还展现出知识底蕴,甚至具备推理才能,乃至拥有上下文学习的本事。
这种现象,使得业界不得不进行反思,那就是,无监督学习所取得的成功,到底是属于偶然出现的工程方面的巧合呢,还是在其背后,存在着严谨的数学以及信息论的根基呢?
核心技术解析:压缩、分布匹配与条件复杂度
将无监督学习与数据压缩相联系,并非全新的洞见。

信息论的开创者克劳德·香农早已指出,预测与压缩是一体两面。
有一个理论框架,它是关于柯尔莫哥洛夫复杂度与Solomonoff归纳推理的,真正把这一理念推到极致的,正是它。
这一框架存在着核心要点,即,存在着具备优秀特质的数据压缩器,其本质情形是在找寻数据之中所蕴含的规律方面以及结构层面。

当我们有两个数据集X和Y,比如说两种语言,要是存在某一个简单函数f,能够把X的分布映射成Y,那么一个强悍到足够的压缩器肯定能捕捉到这种跨分布的共同结构,进而达成对联合数据的更高压缩比率。
这便是分布匹配的实质。

在深度学习这个特定的语境范围之内,随机梯度下降也就是SGD这一概念,实际上是在极为庞大的程序空间当中,去寻觅找寻那能够对数据做出解释的“电路”,它所展现出来的行为,和一个具备可计算特性的压缩器,在很大程度上高度相似。
站在这一视角去看,监督学习能够被视作是一种条件压缩方面的问题,就是在给定输入X的状况下,我们期望能够尽可能以高效的方式去描述(压缩)输出Y。
接着,把所有的数据连接起来,这些数据有文本的,有图像的,还有语音的,连接好后输入进一个功能足够强大的通用压缩器里,在这之后,压缩器为了达成最小化整体描述长度的目的,于是被迫去探寻跨模态、跨领域的共有结构,而这正是理想的无监督学习过程。

现状落地:从iGPT到下一个像素预测的实证验证
理论的生命力在于其可验证性。
前些年以来,朝着去把这种压缩跟那种预测框架运用到实际存在的模型进行的实验,给出了具备强大力度能起到支持作用的呈现。

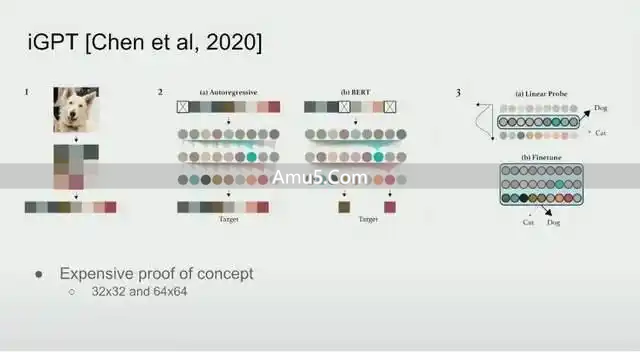
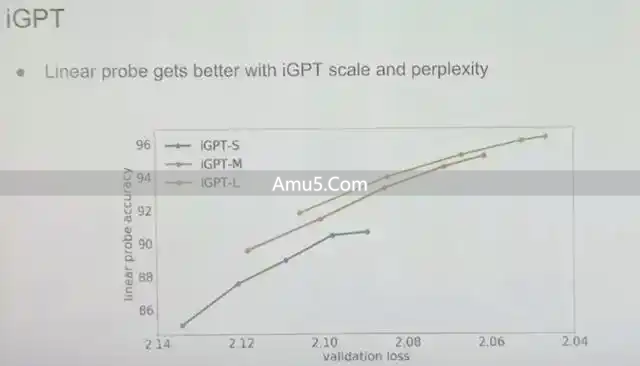
以图像GPT也就是iGPT为代表的研究显示,当我们于图像数据那儿训练一个强大的下一步预测器,就是下一个像素的那种预测器时,模型不但能够生成逼真的图像,而且其学习到的特征表示在下游监督任务里边,像图像分类这种任务中也表现优异哪。
从实验数据可以看出,借助像素级别的无监督预测,模型能够自行发觉图像里的物体边界,以及纹理,还有轮廓,并且这种内部表征的质量,甚至比当时BERT类模型在视觉任务方面的表现还要出色。
这给出了一个关键断定,最难的无监督预测任务,像像素级别的那般预测任务,常常是会迫使模型去捕捉最深层次的生成结构,进而所以就能习得比某些精心设计的掩码任务,就像BERT的掩码语言模型这样的,更具备迁移价值的线性表征呢。
在图像生成领域扩散模型所取得的成功,同样依从了这一逻辑,它们借助学习逐步去噪的进程,从本质上来说是在学习数据的概率分布结构。

未来3–5年趋势:压缩即理解,规模即性能

基于上面所说的框架,往后三到五年的技术发展演变将会展现出几个具有确定性的走向变化趋势。
首先,无监督学习的目标将趋向于更根本的“预测难度”。
就如同当下语言模型已经从下一个词的预测朝着更为复杂的推理路径进行演化,视觉领域的模型不会再满足于粗糙的像素重建,而是朝着能够预测物体物理运动的方向发展,朝着能够预测场景三维结构的方向发展。

预测的难度越高,模型被迫捕捉的结构越深刻。

评判模型架构创新的标准,是看其能不能高效模拟旧架构,并且能不能发现新结构。
由RNN朝着Transformer进行的跃迁,从根本上来说,是鉴于后者具备更高效地捕捉长程依赖结构该种能力。
今后,任何全新架构要是打算带来明显突破,那就得能够凭借更简洁的电路去模拟现有的模型,并且在这个基础上找出那些被现有的压缩器(模型)给忽略掉的深层结构。
多模态融合将迎来真正的理论指导。
现如今的多模态模型大多依赖于对齐学习,然而基于压缩的视角却给出了更为宏大的蓝图,即把不论是文本、图像还是音频以及代码所有这些模态的数据都看作是一个无比巨大的联合文件,交由一个强大到足够程度的模型来进行压缩。

模型性能有所提升,这将直接取决于它去从联合分布里提取跨模态共有结构这样的效率。
风险挑战:计算极限与理论不可计算性
尽管框架迷人,落地路径仍充满挑战。
首先存在着障碍,这个障碍是,在理论层面上,最为完美的压缩器,像 Solomonoff 归纳器这样的,它是没办法进行计算的。

我们当下所运用的SGD,还有Transformer程序,仅仅是这类理想压缩器的有限近似情况。
这有着这样的意味,那就是模型存在陷入局部最优的可能性,并且没办法对某些极为隐晦的结构进行捕捉。
算力与数据的边界依然存在。
纵然无监督学习能够借助海量还未标注的数据,然而要把它压缩到能够用于训练的规模的状况下,会需要呈现指数级增长态势的算力。
模型一旦尝试去捕捉像素级别的那种超高精度的结构之时,它所需要的计算资源就极有可能会逼近在这世上存在着的物理极限了。
我们必须警惕均匀分布的陷阱。

恰如理论所发出的警示,如果数据的分布朝着均匀白噪声的方向趋近,那么所有的无监督学习算法都会出现失效的情况。
现实世界当中的数据,尽管富含着结构,然而,随着模型能力得到增强,剩余那些未被捕捉的“噪音”部分,是否会越来越多,这属于一个悬而未决的问题。
机遇展望:通往AGI的基石与新产业生态
挑战之下,潜藏着巨大的产业机遇。

首先,就企业来讲,无监督学习能力得以提升,这意味着,对于私有数据的利用效率,将会发生质变。
那些有着海量非结构化数据的行业,这些数据像工业传感器日志、医疗影像、法律文书,会能够凭借训练强大的“压缩器”模型,从中提取出远远超越人工标注的商业洞见。

模型评估的标准将发生转移。
将来的模型排行榜,不会再是单纯的基准分数作比较,而是要进行数据压缩率的较量。
一个能更高效压缩特定领域数据的模型,必然是该领域的专家。
压缩理论为解释“涌现”提供了视角。
当模型规模大到能够模拟某一种简单的跨数据分布函数之时,新的能力便“涌现”出来。
这个给我们提示,AGI的达成也许不是依靠某种全新算法的创造,并非是沿着“更好的压缩器”这条道路持续规模化的自然结果。
总结:从工程直觉到科学范式
并非偶然的工程直觉的无监督学习的成功展现,已逐渐演变成基于信息论以及计算理论予以指导的科学范式。
不管是GPT向着下一个词展开的预测,还是iGPT针对下一个像素进行的预测,它的底层逻辑皆是借由去压缩从而发觉结构。
之所以我们会相信,持续扩大数据以及模型规模能够持续提升性能,是由于现实世界的数据结构远远比我们所想象的要丰富。而一个足够强大的压缩器,总是能够在这些数据当中找到还没有被发掘出来的规律。
对于科技行业而言,这既是定心丸,也是冲锋号。
它向我们传达,规模的终点还远远未曾抵达,与此同时,它也给我们以提示,真正的突破会归属那些能够设计出更优良“数据压缩算法”的团队。
针对这场打着压缩旗号的竞赛,谁可以于数据里挖掘出更具深度的结构,谁便能够把控人工智能接下来的十年。
Comments NOTHING