
近年以来,伴随数据规模呈现指数级增长,以及算力成本不断下降的情况,无监督学习,正从机器学习所属的一个理论分支,快速演变成引领产业创新的底层引擎。
不同于依赖人工进行标注的监督学习,无监督学习直接作用于原始数据,其有着能自主挖掘潜在模式的能力,在诸如金融风控,还有用户洞察以及推荐系统等领域,展现出了不可替代的价值。

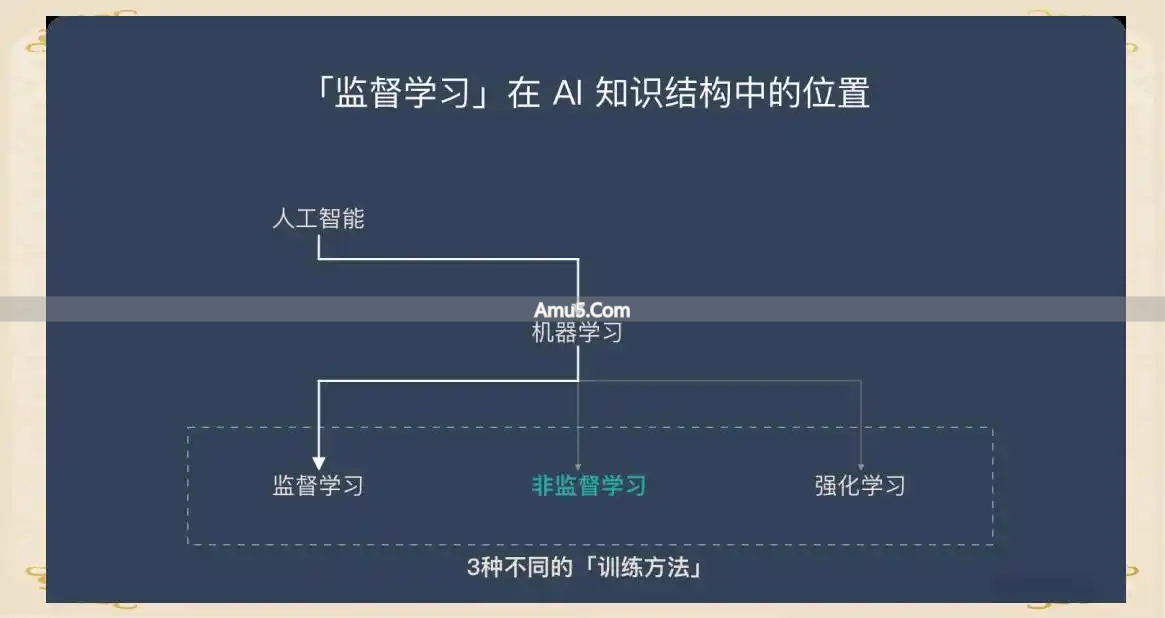
监督学习与无监督学习的本质差异,在于方法论的根本分野。
前一种情况是基于“正确答案”而构建起来的,模型借助对已标注的输入以及输出进行拟合,达成针对特定任务的优化;后一种情况却是在没有标签的那种混沌状况里自行去寻觅秩序。
这么一种“无师自通”的特性,致使无监督学习于面对未知问题之际,或者是标注成本过高的情境之时,显露出极强的适应性。
然而,恰恰是因为它欠缺明确的结果导向,所以对于模型效果的评估经常要依靠间接指标或者业务验证,这就形成了技术落地过程里主要的挑战。
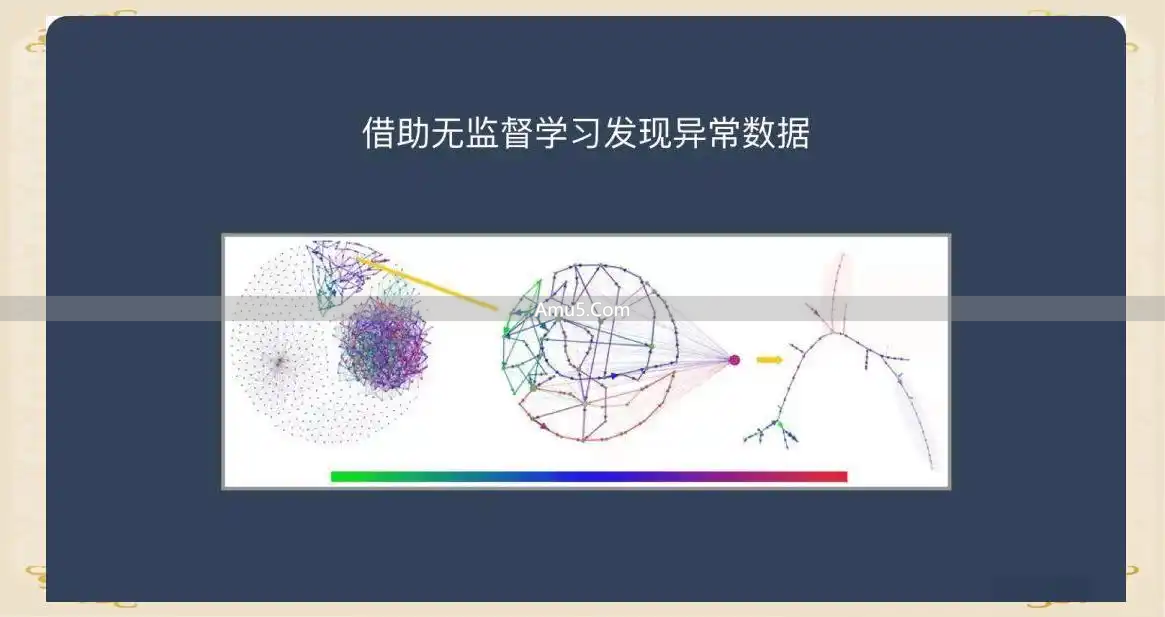
在金融安全范畴之内,异常行为发觉属于无监督学习极其经典的应用情境当中的一个。
就拿反洗钱来讲,非法交易通常会尝试效仿正常行为来躲开监管,然而它在高维特征空间里依旧会展现出跟普通用户的明显偏差。
那种不进行监督的学习算法,并不需要事先去界定什么才叫“洗钱”,单纯凭借对交易出现的频度、金额的分布状况、地域的跳跃等多个方面进行分析,就能够自动地对用户展开聚类操作,并且从中分辨出那些处在主流群体范围之外的,与众不同的点。
这极大程度地减少了对于人工规则以及专家经验的依靠,使得安全系统拥有了能够应对新型且隐蔽欺诈行为的自适应本事。
在商业智能领域,用户细分正经历从粗放向精细的跃迁。
按传统,用户画像大多是以性别、年龄这类静态标签作为主要内容的,然而无监督学习有能力凭借用户的购买行为、浏览路径、点击时序这些动态数据,构建出更具备商业价值的细分群体。逗号隔开的,更具备商业价值的细分群体是被构建出来的,且是依据用户的购买行为、浏览路径、点击时序这些动态数据,而凭借这些靠的是无监督学习,无监督学习有这样的能力,不过传统的用户画像大多只是侧重以性别、年龄这类静态标签作为主要内容。
比如,于同一个电商平台之内,算法有可能发觉“在夜间频繁地浏览母婴用品然而始终都没有下单”的用户群体,这一个群体的心理以及需求显而意见和“径直去下单奶粉”的常规客户是不一样的。
前者被推送育儿知识或者优惠券,其面临的转化效率通常比泛化的广告投放要高。
这正是无监督学习赋能精准营销的核心逻辑。

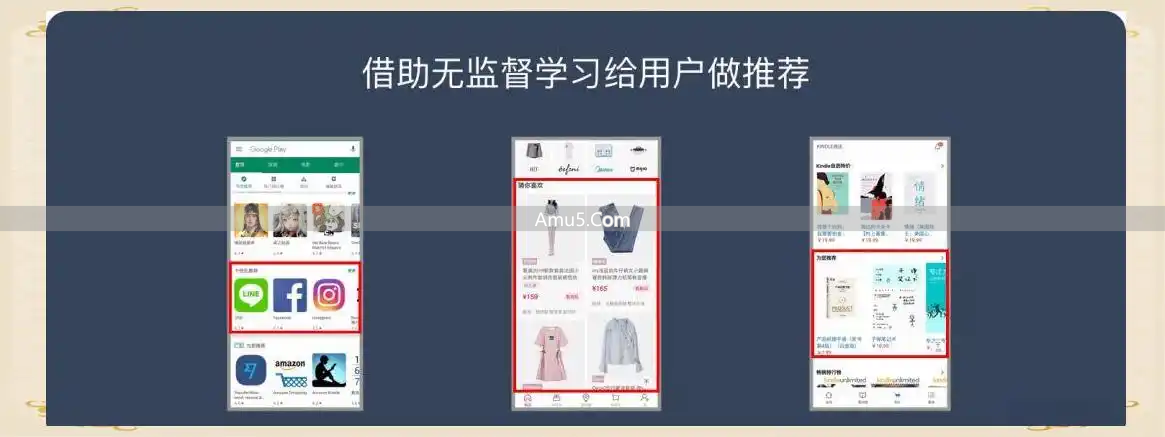
推荐系统则是无监督学习价值最直观的体现。
源自“啤酒与尿不湿”这个经典案例的背后,存在着一种应用,那便是在购物篮分析里,有着叫聚类算法的东西的运用。
系统在对海量用户的购买记录予以分析后,会自行发现商品之间的强关联,或者用户之间的行为相似性,并且顺次生成诸如“购买该商品的用户也购买了”之类的推荐逻辑。
于淘宝、京东等平台,除了有显性的商品关联,像PCA或SVD这样的降维技术,在后台起到关键作用,它们把高维的用户 - 商品交互矩阵,压缩到低维空间,减缓了数据稀疏性问题,还挖掘出潜在的用户兴趣因子。让推荐结果更具泛化能力,也更具解释性。
被最为广泛加以应用的聚类方法之中,存在着一种名为K均值聚类的方法,它所具备的算法逻辑呈现出简洁的特性,并且还具备高效的特点。
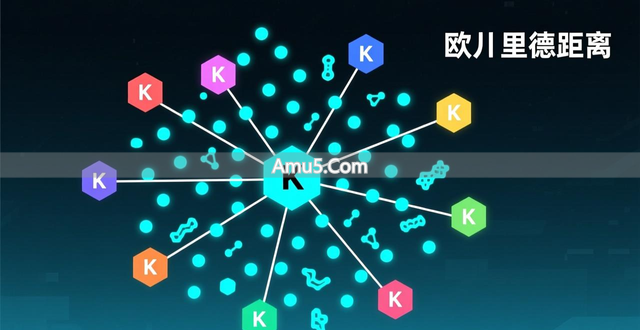
给预先设定好的K值,模型以随机形式进行K个重心的初始化,借助迭代来计算每一个样本到重心的距离,此距离通常是欧几里得距离,随后把样本分配到最近的重心所代表的簇。

随后,算法将更新的重心设定为该簇内所有样本的中心点,而且重复进行分配以及更新的过程,一直到重心不再有明显的移动。
虽说K均值于非凸或者密度不均的数据上所展现的情况有限,然而它的计算效率以及可解释性,致使其在用户分层、图像分割等场景里面依旧占据着主流地位。
当聚类数量难以预判时,层次聚类提供了另一种视角。
它并非要求事先指定K值,而是以自底向上(凝聚)的方式,或是以自顶向下(分裂)的方式,去构建一棵呈现聚类的树状图。
分析师能够依照业务需求,于树状图的恰当层级进行切分,进而获取不一样粗细粒度的分组。
在生物学物种分类里,这种多层次的嵌套结构特别适用,在文档主题层次挖掘等场景中也是如此,然而,它较高的计算复杂度,制约了自身于超大规模数据集上直接的应用有。
与聚类并列的,是旨在降低数据复杂度的降维算法。
主成分分析,也就是PCA,借助线性变换,把原始的高维特征,投射到一组全新的正交维度之上,这组正交维度即为主成分。并且,这些主成分是依据方差贡献度来排序的。
选择留存那几个方差处于最大状态的主成分,如此便能在信息损失量最少的状况之下,极大程度压缩特征维度。
这在数据可视化、特征压缩及噪声过滤中极为常用。
奇异值分解(SVD)则是一种更普适的矩阵分解技术。

它不要求矩阵为方阵,能将任意矩阵分解为三个特定矩阵的乘积。
面对推荐系统,SVD发挥作用,是为补全用户和物品评分矩阵里的缺失值,进而挖掘潜藏着的“用户偏好与物品属性”因子;处于自然语言处理范畴,它被加以运用是以潜在语义分析为目的,最终发现词语跟文档之间隐含的主题关联。
它在数学方面具备优雅性,它在应用方面有着广泛性,这使得它变成跨越多个不同领域的基石工具。
预期未来三至五年的时段内,无监督学习的技术发展会展现出三大趋向态势:首先,和深度学习的相互结合会朝着更深层次推进而深化,像是自编码器、生成对抗网络等深度模型会给予无监督学习更为强大的模式探寻发觉能力;其次,具备可被解释说明的特性将会变成研究的重点聚焦方向,特别是在金融、医疗等有着严格监管要求的领域范围,算法的决策运作过程需要能够向从事业务方面的人员清晰明白地阐释说明;最后,与知识图谱的彼此联合将会催生出更具备因果关联性质的分析探究能力,从仅仅只是单纯性的相关性挖掘朝着更深层次程度的业务方面的洞察认知进行迈进。
然而,挑战依然严峻。
效果评估所具有的模糊性,致使其在落地之际常常需要跟监督学习或者规则引擎进行结合,从而构成混合方案,高维稀疏数据的处理问题,异常簇的语义解释这类问题,依旧需要算法工程师同业务专家展开紧密协作。
对于科技类企业来讲,无监督学习所具备的价值并非是要去替代人工,而是在于在人力根本无法触碰到的数据那深深的海洋之中,率先探测出那些值得予以关注的信号。
只有深切领会其数学本质还有业务边界,才行在智能化转型的潮流里,切实释放数据的潜能。
Comments NOTHING