
在2025年4月,于苏州金鸡湖国际会议中心,举办了中国移动云智算大会,会上,一个关键议题,关乎AI产业底层架构,被推向了台前。
AI大模型参数规模突破万亿级别时,对于算力需求呈现指数级增长,然而芯片能效却是提升缓慢的,这两者之间所存在的矛盾,正成为高悬在行业头顶上的那柄达摩克利斯之剑。
亿铸科技,是存算一体领域的创新代表,在此次大会之中揭示了一条全新路径,此路径是关于后摩尔时代算力突围的。
当下,AI算力发展那些核心的瓶颈之处,从本质上来说,是一场因为架构存在的缺陷从而引发的效率方面的危机。
传统芯片,是依照冯·诺依曼架构构建的,其计算单元跟存储单元在物理层面是相互分离的,数据于这两者之间频繁地进行搬运,进而造成了极大的功耗以及时间延迟,也就是被称作“存储墙”的问题。
熊大鹏博士于演讲期间引用某款R1大模型一体机的实测出来的数据,以直观的方式揭示了这样的一个困境,即一款理论算力高达20PFLOPS的系统,在实际去运行大模型的时候,有效算力折损率居然超过了90%。
这表明,占据绝大部分比例的功耗以及硬件投入,均耗费在了数据的搬运方面,而非进行实际的计算之中了。
在AI模型复杂度,持续不断飙升的这种环境背景之下,这样一种“功耗墙”,与“存储墙”的叠加所产生的效应,正在迫使行业,重新去审视底层计算架构的合理性。
面临这样一种困局,仅仅凭借制程的微缩所带来的红利,已然显现出疲态,产业迫切需要从计算范式的层面,展开颠覆式的创新。
亿铸科技所提出的架构,是全数字存算一体架构,它恰恰是针对这一痛点作出的精准回应。
此技术借由把存储单元跟计算单元于物理层面深度交融,致使数据在“原地”就能达成计算,从根源上消弭了数据搬运所带来的开销。
根据阿姆达尔定律,系统的加速上限取决于不可并行部分的比例。
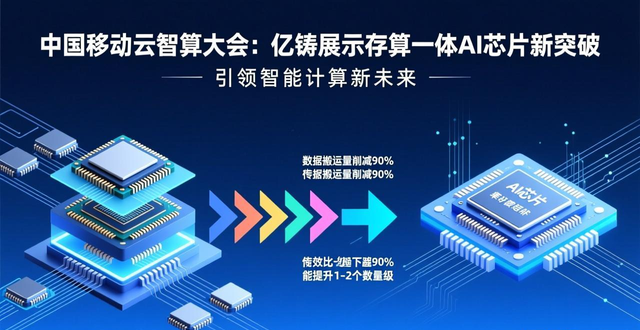
于传统架构里头,数据搬运占有大量串行时间,变成性能提升的瓶颈所在;然而存算一体架构能够把数据搬运量削减超过90%,致使串行开销趋向于零,进而在宏观层面带来1至2个数量级的能效比提升。
这种架构,缓解了功耗压力,还于同等工艺条件下,释放出了更高的有效算力密度,为大模型的本地化部署,以及云端算力升级,提供了极具商业价值的解决方案。
技术创新能否落地,生态兼容性是关键考验。
于软件层面,亿铸科技所推出的YICA自研软件栈,其目的在于,降低从CUDA生态迁移至存算一体架构的门槛。
此软件栈对主流深度学习框架予以支持,借由算子“一键生成”以及自动编译优化,大幅削减开发者的适配成本。
测试数据表明,于兼容模式当中,模型迁移成本能够降低大概70%,此情况针对那些急需快速开展大模型应用部署的企业来讲,毫无疑问地减少了技术切换的风险以及试错成本。
此种“硬核之创新与软性之兼容”的策略,恰是新兴技术切入成熟生态,达成快速落地的明智行为。
站在行业的视角去看,亿铸科技所呈现出来的路径,并不是志在完全颠覆当下已有的计算体系,而是要为AI算力的供给开拓出“第二条增长曲线”。
于传统架构趋近物理极限的此刻,存算一体给云计算数据中心,给予边缘智能节点,还供给端侧设备,献上了更为优良的能效抉择。
特别是在大模型朝着行业应用进行渗透的进程当中,高昂的能耗以及算力成本是规模化落地的主要阻碍因素,能效比的跃升会直接转变为TCO(总体拥有成本)的降低,进而加快AI在各个垂直行业的渗透。
AI芯片之间的竞争,会从仅仅只是单纯的算力进行堆叠,转变为架构效率以及生态粘性方面的综合较量。
亿铸科技依靠其于器件、电路、架构直至软件的全链条研发能力,并且核心团队拥有超过25年的产业化经验,正着手构建一条从底层技术至上层应用的完整护城河。
眼下,产业界对于算力能效比的关注程度,正持续不断地升温,在此情形下,以存算一体作为典型代表的新型计算架构,有希望在未来时段的AI算力格局里面,占据那种有着至关重要意义的地位,进而推动整个相关行业,从那种“比拼算力”的状况,朝着“比拼效率”的方向,产生深刻的变革。
Comments NOTHING