
于数据库设计范畴之内,自现实世界的业务所需转变为机器能够存储的结构化数据,这中间要历经概念结构设计跟逻辑结构设计这两个具有核心性质的阶段。
概念设计所追求的目标在于,清晰地审定业务领域里的“实体”以及“实体间联系”,逻辑设计却承担着把这些概念模型转变为具体的关系模式(也就是数据表)的职责。
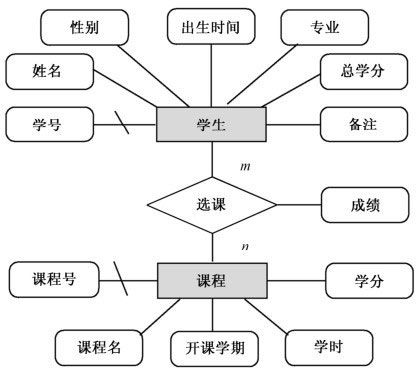
把学生成绩管理系统当作例子,它的核心业务是围绕着“学生”以及“课程”来开展的,这给理解数据库设计提供了非常好的范本。
一、概念结构设计:构建E-R图
概念设计通常借助实体-联系图(E-R图)进行信息世界建模。
其基本元素包括:
实体型:用矩形表示,即同类数据的集合。
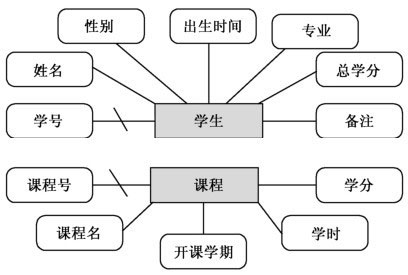
例如,系统中的“学生”和“课程”就是两个独立的实体集。
属性:用椭圆形表示,用于描述实体的特征。
具“学生”之称,其为实体集,此实体集里头藏括之物有学号,有姓名,有性别,有出生时间,有专业,有总学分,还有备注等这般属性。
有这样一组情况,在其中,用于唯一标识每一个具体学生的属性或者属性组合,被称作是“码”(Key),举例来说,“学号”就是学生实体的码。
联系:用菱形表示,描述实体集之间的行为规则。
E-R 图进行设计期间,最为关键的那一步是去确定实体之间的联系类型,此联系类型会直接对后续数据库表结构的设计策略产生决定作用。
联系主要分为三类:
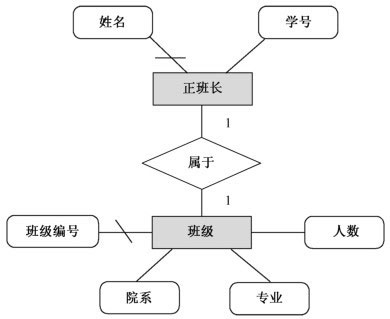
1. 一对一联系(1:1):例如“班级”与“正班长”。
一个班级只有一个正班长,一个正班长仅属于一个班级。
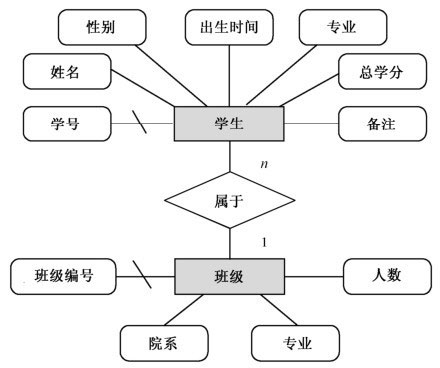
2. 一对多联系(1:n):例如“班级”与“学生”。
一个班级可以有多名学生,但一个学生只能隶属于一个班级。
3. 多对多联系(m:n):例如“学生”与“课程”。
一个学生可以选择多门课程,一门课程也可以被多名学生选修。
二、逻辑结构设计:E-R图向关系模式的转换
在完成绘制E-R图之后,需要把它转变为数据库管理系统所支持的关系模式。
这一过程遵循明确的转换规则,以确保数据的完整性与存储效率。
1. 实体集向关系模式的转换
每一个实体集都应转换为一个独立的关系模式(即数据表)。
实体的属性即为表的字段,实体的码即为表的主键。
例如:
表示学生的表,其中包含学号,还有姓名,此外有性别以及出生时间,再加专业以及总学分,另外还有备注。
课程表:课程(课程号,课程名,开课学期,学时,学分)
2. 联系向关系模式的转换
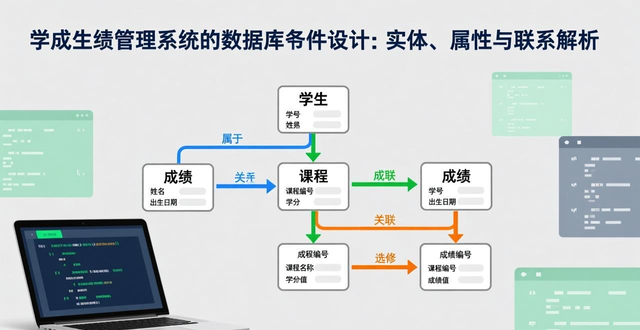
联系的转换规则取决于其类型,这是逻辑设计的核心。
1:1联系的转换:
这种联系一般不会单独去构建表格哟,而是会把联系所产生的那些属性以及一方的主键给提取出来,然后添加到另一方那里当作外键呢。
例如呀,能够把“班级”表的主键“班级编号”增添到“正班长”表里头,或者反过来操作,以此降低表的数量,进而提高查询的效率。
1:n联系的转换:
最常用的方法是“外键下沉”。
在“n”端实体集也就是学生表之中,添加“1”端实体集上诸如班级编号的那个主键用作外键。
如此这般,能够清晰无误地表达出“一个班级对应多个学生”这种隶属关系,并且还规避了因额外建表而引发的数据冗余现象。
m:n联系的转换:
必须为m:n联系单独创建一个新的关系模式。
因为这种联系无法通过简单地在原表中增加字段来表达。
比如说,存在于“学生”跟“课程”二者之间的“选修”这种联系,得去创建出一个“选课成绩表”。
该表得包含“学生表”的主键也就是学号,以及“课程表”的主键即为课程号,要把这两者组合起来当作该表的联合主键,并且还能够包含描述此联系的属性,像“成绩”以及“选修时间”。
其结构如下:
选课成绩表:选课(学号,课程号,成绩,选修时间)
利用这样的途径,繁杂的多对多关联被明明白白地拆分成了两个一对多关联,契合关系数据库的规范化规定。
三、数据库物理设计与运维优化
把E-R图成功予以转换,使之成为关系模式之后,紧接着的物理设计以及运维,乃是保障系统性能的关键所在。
1. 索引优化:
在学生成绩管理系统中,查询操作往往集中在某些字段上。
除去主键所属的聚集索引不说,应当于常常会被当作查询条件或者连接条件使用的外键之上构建非聚集索引。
比如说,于学生表里头名为“姓名”此一字段之上构建索引,能够加快按照名字来进行检索的速度;在选课成绩表之中名为“学号”以及同样名为“课程号”这两个上面建立复合索引,可以明显提高多表关联查询的速率。
但是需要留意,索引可不是越多就必定越好,数量过多的索引会使得数据写入(INSERT/UPDATE/DELETE)的速度被拖慢。
2. SQL操作规范:
在进行SQL编写期间,应当防止于索引列之上运用函数或者进行计算,如此这般便是会致使索引失去效用从而无法正常发挥作用的呀。
比如说,WHERE YEAR(出生时间) = 2000这个式子,其应该被改写成为,WHERE 出生时间 >= '2000-01-01',并且,出生时间 < '2001-01-01'。
在进行多表连接查询这个操作之时,要明确地、确切地指定连接具备的条件,并且优先去选用INNER JOIN这种方式,而不是选用那种隐式存在的笛卡尔积方式。
3. 运维技巧与范式权衡:
依据严格遵循规范化设计的情况,针对特定呈现高并发特点的查询场景,能够适度引入反规范化设计。
假如,要是需要频繁地同时去进行学生信息以及其总学分的展示,那么能够把“总学分”当作冗余字段直接存放在学生表里面,虽说这违背了第三范式,也就是存在传递依赖的情况,不过凭借着减少每次查询之际的实时计算开销,达成了用空间来换取时间的目标,这在数据仓库或者高流量业务库当中是极为常见的。
从对E-R图做需求分析开始,接着到对关系模式进行严谨定义,而后又到物理层的索引调优以及SQL优化,这样一整套流程构成了数据库设计的完整闭环。
对实体与联系的本质予以深入理解,开发者得以构建出数据存储系统,该系统结构清晰,冗余度低,于复杂业务场景下,能保持高性能与可扩展性。
Comments NOTHING