
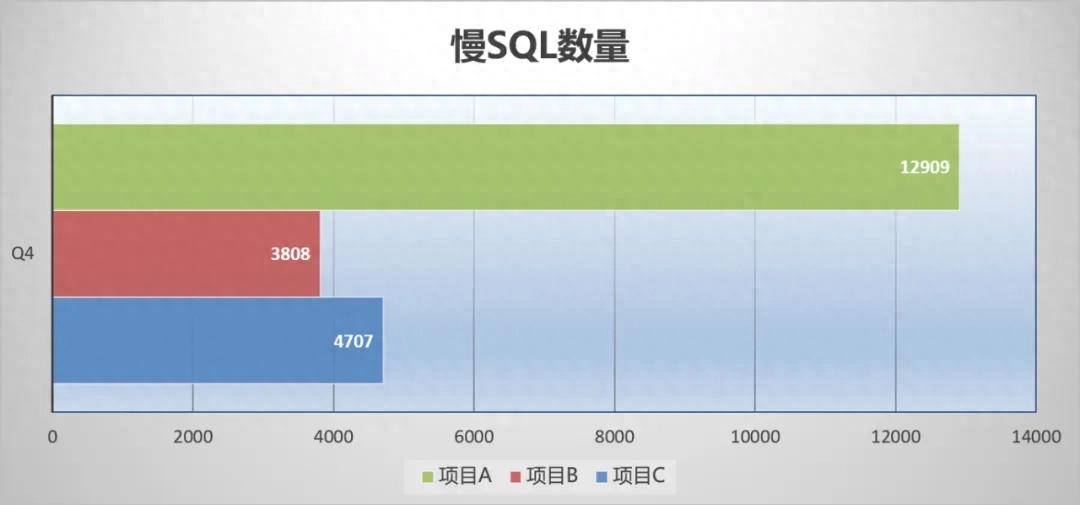
活动中台系统的核心命脉聚焦于数据库性能,慢SQL恰似血管里的血栓,它对用户体验以及业务运转效率有着直接影响,在这儿,本文会深入剖析数据库性能问题产生的根源,并且给出实战的解决办法。
索引缺失的代价
在查询语句所关联的条件列未构建索引的情形下,数据库就必须得去执行全表扫描的操作。
举个例子,有个电商活动平台,一张存有用户参与记录的表格,里面含有5000万条数据,然后,在没有索引的状况下,去查询特定用户的活动记录,花费的时间长达15秒。
建立合适索引后,同样的查询语句执行时间降至0.03秒。
索引如同书的目录那般,它能够助力数据库迅速定位目标数据,进而避免出现诸如进行逐行扫描所带来的那种极为巨大的I/O开销。
查询条件的陷阱
复杂的查询条件往往成为性能杀手。
在某项目里,开发人员运用了多层嵌套的子查询,还进行了六个表来进行JOIN操作,单次查询所耗费的时间为8.2秒,这远远超过了1秒的慢SQL阈值。
将复杂逻辑拆分成为两次简单查询的优化后的查询,于应用层开展数据组装,执行时间被缩短到0.5秒。
针对面向用户的那种具有高并发特性的业务而言,应当尽可能地去规避在数据库这个层面开展复杂算术运算。
数据量膨胀的威胁
select * from a where id = 0;同一组SQL语句,于数百万级别的数据表之中运行仅需0.1秒,而当数据量扩充至数亿时极有可能飙升至5秒之上。
某个活动中台体系当中的积分记录表格,历经三年发展,积攒起了总计2.3亿条的数据量,从而致使日常进行查询操作的时候,频繁出现超过规定时间得不到反馈的状况。
select result from a where id = 0;数据清理是最直接的解决方案。
CREATE TABLE `table_test` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`test` varchar(128) NOT NULL DEFAULT '' COMMENT '索引测试字段',
............
`result` varchar(128) NOT NULL DEFAULT '' COMMENT '结果测试字段',
PRIMARY KEY (`id`),
KEY `test` (`test`),
) COMMENT='记录表';将三年前的历史记录进行分批删除,每一批次仅仅处理1000条,并且每一批次处理之间间隔2秒,如此一来,既实现了存储空间的释放,又达成了避免对线上业务产生冲击的目的。
数据库设计的反思

过度范式化设计会导致查询需要关联过多表格。
某项目把活动信息去拆分,分成基础信息表,扩展属性表,统计信息表等八个子表,每一次查询都得去进行七次JOIN操作。
凭借对部分字段进行合理的冗余操作,伴随高频查询的那些字段被合并进主表里头,查询性能实现了80%的提升幅度。

数据库设计需要在范式化和性能之间找到平衡点。

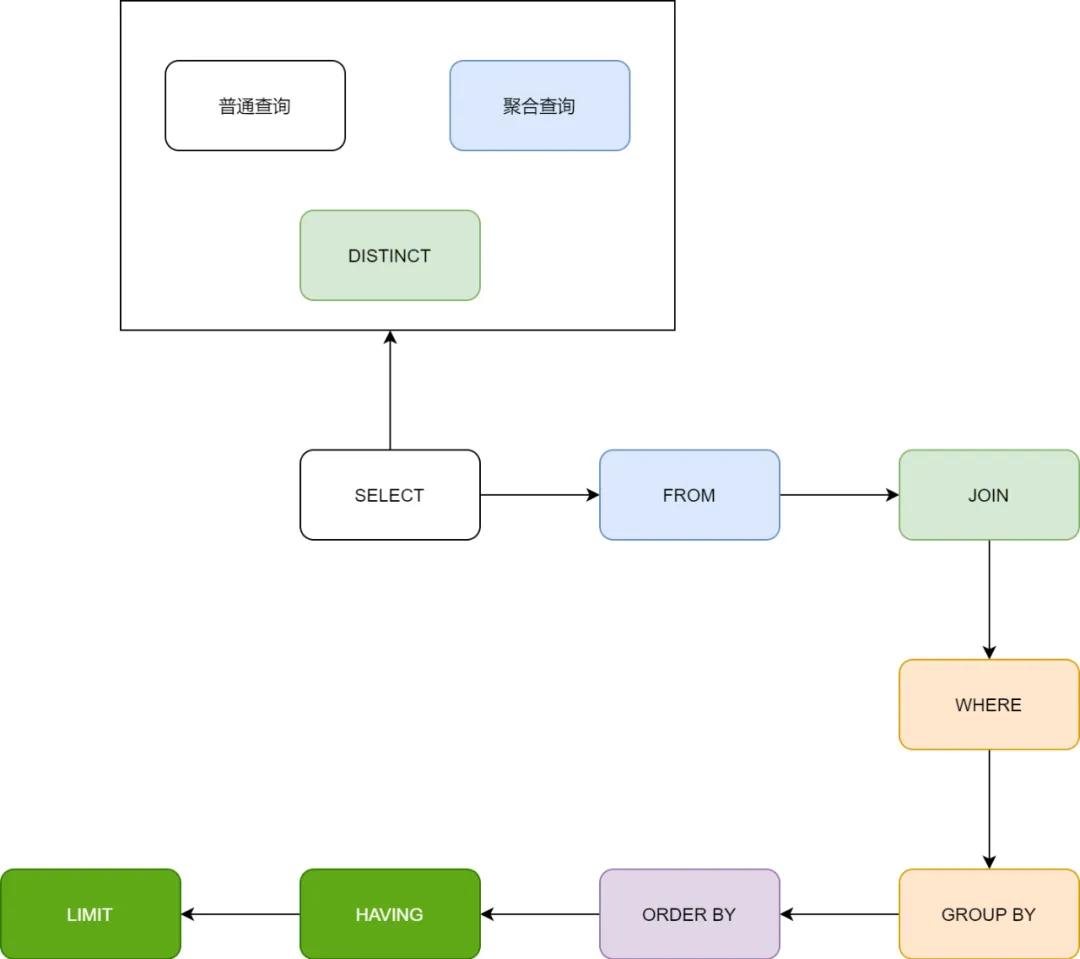
SQL语句的精简艺术

不少开发人员惯于径直查询整个DO对象,而后返回二三十个字段,然而实际上业务所需仅两三个字段。
某次对账查询返回了42个字段,执行耗时3.6秒。
优化为只查询需要的4个字段后,执行时间降至0.4秒。
裁减数据传输量,削减数据库处理负载,这是提升 SQL 效率最为直接的手段。
select * from a left join b on a.id = b.id where a.id = 0;交互策略的整体优化
处理每日凌晨时段的历史数据清理工作,原本的方案运用单一大范围扫描而后删除的方式,致使数据库负载急剧上升。
select * from a where id = 0;
select * from b where id = 0;优化之后,引入智能删除的策略,优先借助活动信息,以及分表路由,精准地定位待删除的数据。
配置项能够灵活地去指定分表的数量,具备查询时的条件,拥有每次删除的数量,以及时间范围。
对于存有活动信息的数据,先去查询活动,接着定向删除指定的分表,如此一来做到了清理效率提升15倍,并且彻底消除了慢SQL风险。
select * from a where id in (select id from b) and time > '2024-03-29';你在项目实战中是否也遇到过棘手的数据库性能问题?

在评论区域能够分享你自身的优化经验,这是被欢迎的,去赞成并收藏这篇文章,从而让更多的开发者从中获取益处!
Comments NOTHING