
会不会并发编程,这可是划分普通程序员与高级程序员的一道界限。好多人写了好些年代码,碰到多线程、多进程、多协程时依旧稀里糊涂,要么就只会一种模式,换个场景就不行了。今儿个我们从实际操作角度,把这三种并发方式彻彻底底拆清楚,告诉你在啥场景该用啥,以及怎么用能让程序有着十倍的效率。
多线程被GIL坑了这么多年依然有人用
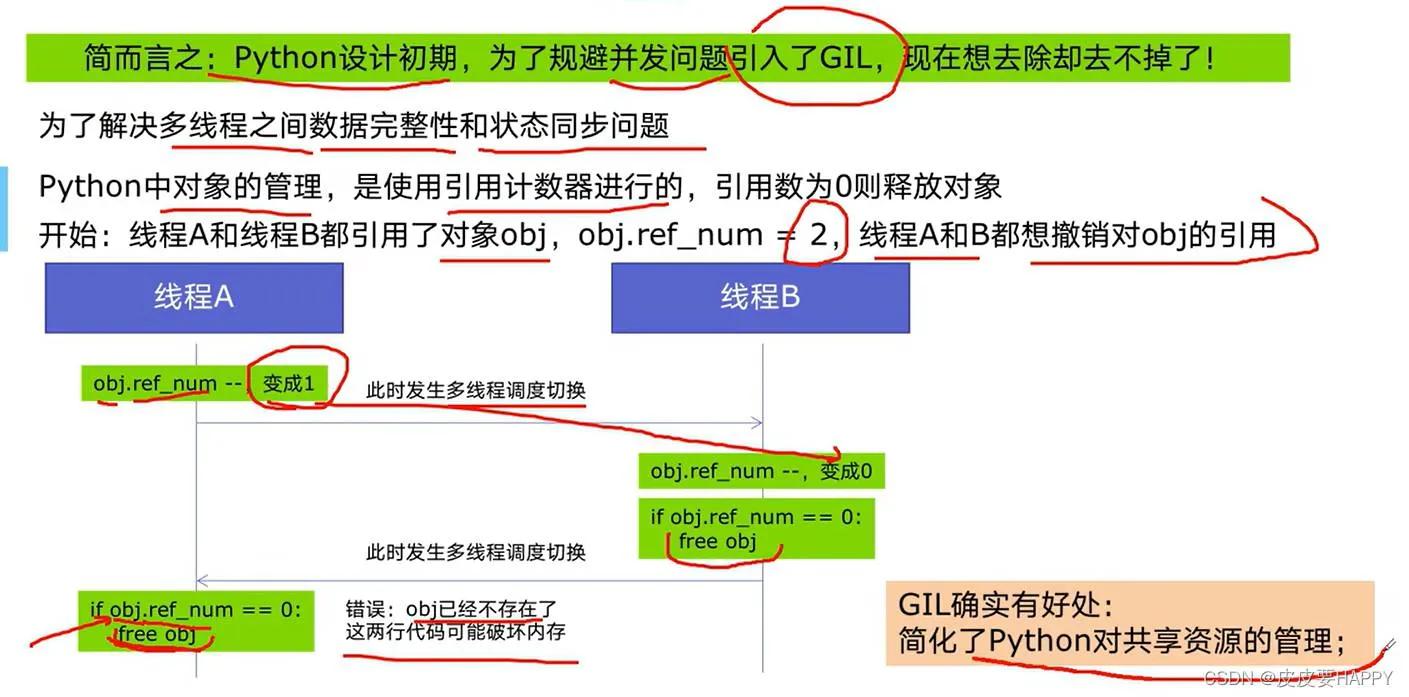
很多刚接触的新手错误地认为Python多线程能够借助多核,然而实际上全局解释器锁GIL致使它在CPU密集型任务当中仅仅是个花瓶。到了2026年Python 3.14依旧保留着GIL,这属于CPython解释器的历史遗留下来的问题。多线程的真正具有优势的地方在于IO密集型任务,像是网络请求、文件读写,原因是线程在等待IO的时候会释放GIL,其他的线程便能够接着运行。但需要留意的是,线程并非是免费的,一个进程开启几百个线程内存便会紧张,频繁的上下文切换同样能够把性能消耗掉一半。在实际场景当中,运用concurrent.futures.ThreadPoolExecutor去对线程数量加以控制属于常规的操作行为,通常情况下不会超出CPU核心数的五倍。
多进程才是CPU密集型的真解药
要是你从事视频编码,以及图像处理,还有科学计算方面的工作,那么多进程便是唯一能够将多核CPU全部利用起来的办法。每一个进程都有着独立的解释器,以及内存空间,能够完全避开GIL。在2025年的时候,阿里云的某一个部门利用multiprocessing库把视频转码的速度提高了8倍,20个进程能够使40核服务器达到满负荷运行。不过需要付出极大的代价:进程启动比较缓慢、内存开销非常高、进程之间的通信十分麻烦。如果开启上百个进程,操作系统调度器会直接发出警报。因而在实际战斗当中,多个进程通常会结合进程池来加以运用,进程的数量一般而言不会超出CPU核心的数量,以此来防止过度的竞争情况出现,跨越进程的数据传递借助Queue或者共享内存来达成,不过要记住一点:倘若能够传递引用的话,那就不要传递数据了。
多协程让IO密集型任务跑出核动力
未来2026年必定成为标配技能的协程,能在单线程当中借助事件循环达成超乎寻常的高并发,以asyncio来编写爬虫程序,单机状态下能够轻松维持数万个连接,而这样的数量级别是线程以及进程永远都无法企及的,在2024年知乎进行后端重构工作时,将部分线程池服务替换成协程之后,8核机器从原本只能支撑2000的并发量提升到了5万并发量,并且内存占用反而下降了60%,然而协程存在着难以克服的短板,那就是你必须使用支持异步操作的库,像是用aiohttp去替代requests,用aiomysql去替代pymysql。将传统同步代码转变为异步,偶尔之时是需要对整个调用链予以重新编写的。此外,协程适宜于IO密集型,一旦碰到纯计算任务,依旧得老老实实地交还给线程或者进程。
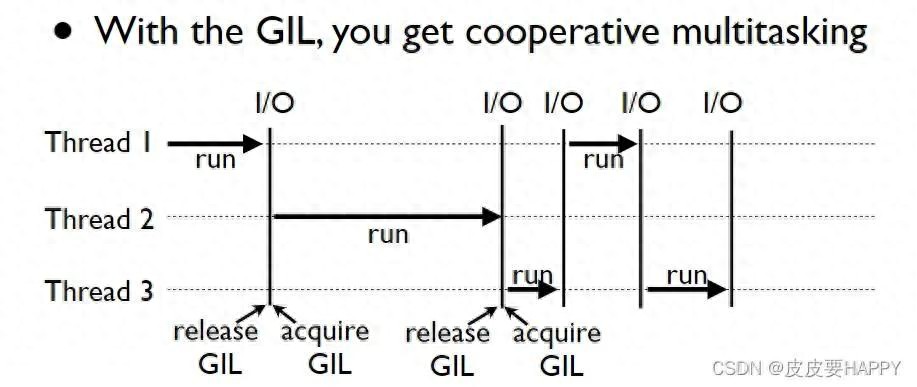
全局解释器锁GIL不是Bug是设计
1992年Python被发明之际,多核CPU尚未普及开来 ; GIL是基于简化内存管理而存在的 ; 它使得在一个进程里,同一时刻仅有一个线程去运行Python字节码 ; 这样的设计,让C扩展模块编写起来变得容易一些,并且也保住了单线程的性能 ; 但是其代价就是,如今每个Python程序员都不得不为并发选型而感到头疼 ; 有人提议将GIL去掉,在2023年出现过nogil分支,然而兼容性问题过多,直至如今都没有被合入主线 ; 所以当前的状况就是:你即便对它咒骂千百遍,仍旧得与它共同存在。明白GIL,并非是为了去喜爱它,而是要晓得何时去避开它,何时去运用它。
规避GIL限制的四种实战套路
第一招:对于IO密集型,采取多线程加协程进行混搭的方式,让线程去运行事件循环,而协程则负责运行任务。第二招:要是遇到CPU密集型,那就直接采用多进程,即便multiprocessing存在复制数据这种情况也没有其他办法了。第三招:针对一些起关键作用的计算模块,运用C扩展,举例说明就是例如numpy、opencv是在C层面释放GIL的。第四招:倘若实在不存在可行的办法,那便更换解释器,像Jython、IronPython由于没有GIL,仅是其生态难以跟得上。2026年,深圳的某个量化团队,在回测系统当中,用Rust重新编写了计算核心,借助Python FFI进行调用,从而完全绕开了GIL,使得回测速度提高了14倍。要是绕不开,那就换个途径,在如今这个时候,没有人会一味地死磕纯Python计算。
多线程爬虫案例速度实打实快10倍
某个于2025年的爬虫外包项目,其目标网站为电商评论接口,以单线程进行爬取时,一日仅能获取200万条,后采用ThreadPoolExecutor开启32个线程,致使带宽得以满负荷运行,历经3小时便成功搞定600万条。那为何未曾采用协程呢?缘由在于目标站点TLS握手所产生的开销颇为巨大,并且aiohttp在当时存在兼容方面的问题。虽说线程存在一定的重量,然而requests库所构建的生态体系较为完整,在出现错误时重试的逻辑相对易于编写。速度之所以能够提升,并非源于线程并行执行,而是在于等待响应的间隙,其他线程能够开展工作。这告诉我们:工具选对场景,菜刀也能砍树,别非要掏电锯。
你于实际项目里所运用的是多线程、多进程亦或是协程呢,碰到过因选错并发模型致使线上崩溃的事故吗,欢迎在评论区分享你的翻车经历,点个赞能让更多同行避开这些坑。
Comments NOTHING