
你于网络之上搜寻数据库迁移,十篇文章之中有九篇会告知你“运用这个工具便可以”。然而,切实令你难以入眠的是:怎样在不停歇机器运转、不进行回滚失败操作、不将用户搁置在半途的情形下,把新的模式推行上去。倘若这件事情搞不定,天亮之时就要承担责任。
微服务迁移的核心不是代码而是数据
一种典型存在的双层层级架构情况是,上面呈现的是十几个处于无状态状态的微服务副本,而下面则是那一个谁都绝对招惹不起的数据库。你于API之中添加了一个字段,代码进行了修改,然而数据库却并不认识它。这种情形被称作前后不匹配。
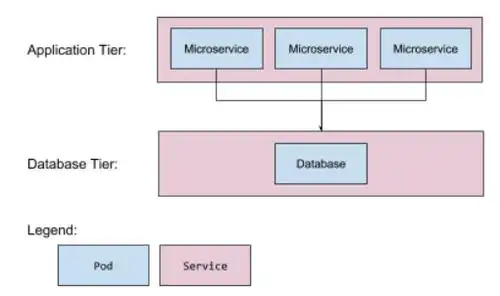
截至2026那时候,仍在运用“先停机再升级”这种方式的团队,数量要高于你所想象的,有很多。某个从事电商业务的公司,就在去年双十一前夕,出现迁移脚本运行崩溃的状况,进行回滚操作消耗了40分钟时间,直接估算的损失超过300万。数据层面是不能轻易变动的,然而不变动又不可以。这并非是技术方面的问题,而是涉及信任的问题。
那种迁移的本质并非是去编写脚本,而是要在达成确保终端用户没有任何发觉的前提状况之下,使得新旧这两套代码都能够正常地开展工作。这所蕴含的意思是,你所涉及的数据库模式一定要做到向后兼容,并且旧版本的代码上线之后不能马上就出现报错状况。
版本化迁移脚本是唯一靠谱的起点
将数据库模式如同代码那般纳入版本管理,这并非是选项而是底线,每一个变更都对应着一个带有版本号的SQL脚本,依照顺序去执行,启动的时候检查当前库版本,若不够则运行迁移。
2019年起,某家金融科技公司硬性规定,所有服务都得借助Flyway来管理数据库变更。历经三年,生产事故减少了六成。并非工具具有多么神奇的功效,而是它使得“数据库状态能够被追溯” 这一情况 变成了一种习惯。
然而版本化仅仅处理好了‘怎样开展修改’,并未处理‘何时展开修改’。要是你于服务启动之际才去运行迁移,并且迁移需要运行两分钟,那么在这两分钟之内打进来的请求全部都无法连接到库。你或许并未出现宕机状况,可是与宕机不存在差别。
就绪探针不是摆设得替它操心

只看容器有无启动的Kubernetes默认就绪探针,你的Java应用启动用时45秒,可在迁移仅跑了30秒时就告知“我好了”,负载均衡器随即将流量打入,此时数据库连接池尚未准备好,致使第一批请求全部失败。
真正正确的做法是,在HTTP服务器开始启动之前,手动去跑完迁移这一操作,接着建好连接池,随后做完热身,之后再去告诉K8s“我现在能够接客了”。Shopee里面某一个团队在2025年的时候做过统计,仅仅只是依靠优化就绪探针的检查时机,在发布期间的5xx错误就减少了87%。
别寄希望于由系统自动设定好的初始状态来为你考虑周全,由系统自动设定好的初始状态仅仅确保了相应程序处于运行状态,却并未确保相关业务得以顺畅行驶。
存活探针不能只查进程活着没
更加隐蔽的问题在于,进程处于存活状态,可是业务却已然死亡。数据库连接池遭到了破坏,线程陷入卡死状态,请求排队直至超时。在这个时候,K8s尽管看到进程仍存在,却什么都不采取行动,用户只能干巴巴地等待。
应当模拟一个真实的、轻量级的业务请求,这才可谓是合理的存活探针。比如说去查询一条必定存在的数据,又或者调用一个仅为读取的接口。倘若连这个都遭遇失败,那就意味着这个Pod已然没有继续存活的资格了。
Netflix的工程实践当中存在一条硬性指标,那就是存活探针必须经由业务层通过,而不能够仅仅去查看端口是否通畅。这是因为他们曾遭遇过问题情形,也就是端口处于通畅状态,但是进程也在运行时,数据库却无法进行连接了。当时整个集群耗费了15分钟才察觉到这个问题。
回滚不是按撤销键是两套代码共存
有不少人想法是,回滚这一行为呢,就是把新版的代码给撤下来,然后将旧版的代码推上去。然而呀,数据库已然发生改变了,旧版代码它并不认识新添加的列,会直接崩溃给你看的。
故,真正具备的回滚能力,乃是于发布之前便设计而成的。你增添了一个字段,在代码当中需确切写明SELECT哪几列,而非SELECT *。如此一来,旧版代码获取到新数据,虽不认识多出的字段,却也不会报错。
一个更具彻底性的方案乃是进行双写,新版本同时展开对旧表以及新表的写入操作,在切割流量之前先行验证数据的一致性,某出行平台于2024年对订单库予以重构期间,双写行为整整持续了两周时间,先是确认不存在任何差异之后才正式实施切换,其代价是开发成本实现翻倍,不过却换回了“回滚无需对数据库进行操作”这样一张底牌。
可观测性不是锦上添花是救命稻草
没在滚动发布时,凭借Weave Cloud这类工具一眼瞧出新版本Pod所接收到的请求并非全都报错,你便永远不能晓得某个变更究竟有无问题,除非你能够瞧见实时的流量分布以及错误率。
2025年,GitHub出现一次大规模的宕机情况,事后进行复盘时,最为重要的教训是,发布期间具备关键指标的看板,没有被放置在作战室的大屏之上。工程师凭借自身感觉表示“应该不会有问题”,而后花费了三小时进行回滚操作。
进行可视化操作,并非是为了达成好看的目的,而是要在错误蔓延至十分之一用户的情形提前之前,将其控制住。
你的最近一回进行数据库变更,究竟是切实能够底气十足地宣称“绝对不会产生差错”,还是仅仅是在冒险猜测它不会在凌晨两点出现崩溃情况?
Comments NOTHING